
Day103 Deep Learning Lecture Review - Lecture 18 (2)
Data-Centric AI: Active Learning, SEALS(Similarity Search for Efficient Active Learning), Dataset Pruning, and Data Engine

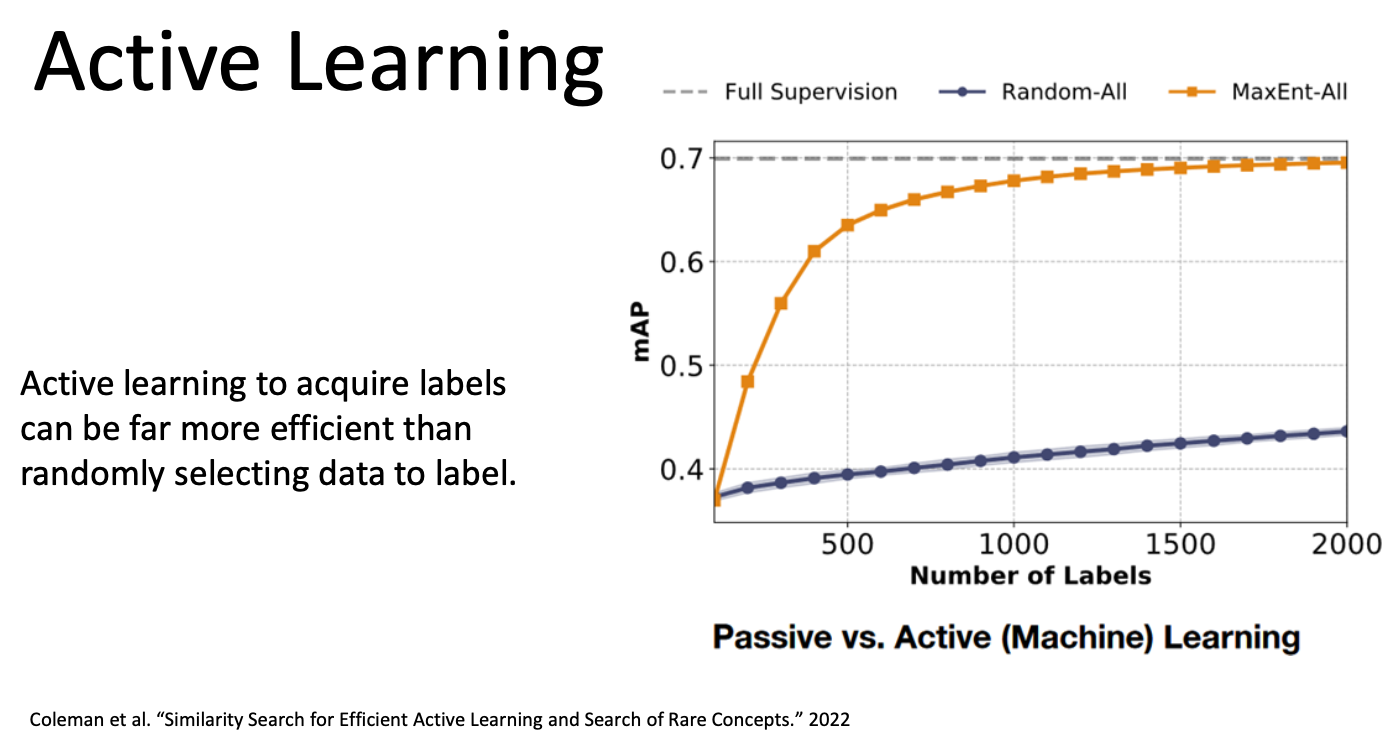
Selecting Data to Label
Active Learning for Efficiently Labeling Datasets
Active Learning is an iterative process to label data points to maximize the model’s performance. Instead of randomly labeling data, it identifies the most informative samples to label next.
- Method for determining which samples from a large unlabeled data pool to label would maximally improve models.
- Active learning is a method for efficiently getting labels for datasets.
-
Pool-Based Active Learning:
- Unlabeled Data Pool
- Begin with a large pool of unlabeled data.
- Initial Labeling
- Label a small subset of the data to train an initial model.
- Select Informative Samples
- Use the trained model to rank unlabeled samples by uncertainty (e.g., entropy or margin sampling).
- Choose the most uncertain samples to label in the next round.
- Iterate
- Retrain the model with the newly labeled data and repeat the process.
- Retrain the model with the newly labeled data and repeat the process.
- Unlabeled Data Pool
-
Determining Which Samples to Label
- For each round of active learning, we need to identify the samples we want to label.
- Most methods use uncertainty sampling, where we select samples to label what the model is most uncertain about.
- Two standard methods for scoring data are maximum entropy (MaxEnt) and Information Density (ID).
- MaxEnt: $\phi_{\text{MaxEnt}}(z, A_r, P_r) = - \sum_{\hat{y}} P(\hat{y} \vert z; A_r) \log P(\hat{y} \vert z; A_r)$
- ID: It uses MaxEnt and also cosine similarity between embeddings. $\phi_{\text{ID}}(\textbf{z}, A_r, P_r) = \phi_{\text{MaxEnt}}(z) \times \left( \frac{1}{\vert P_r \vert} \sum_{z_p \in P_r} \text{sim}(z, z_p) \right)^\beta$
- $A_r$ is the model at round $r$, $\textbf{z}$ is an embedding, and $P_r$ is the set containing the unlabeled pool.
- $A_r$ is the model at round $r$, $\textbf{z}$ is an embedding, and $P_r$ is the set containing the unlabeled pool.
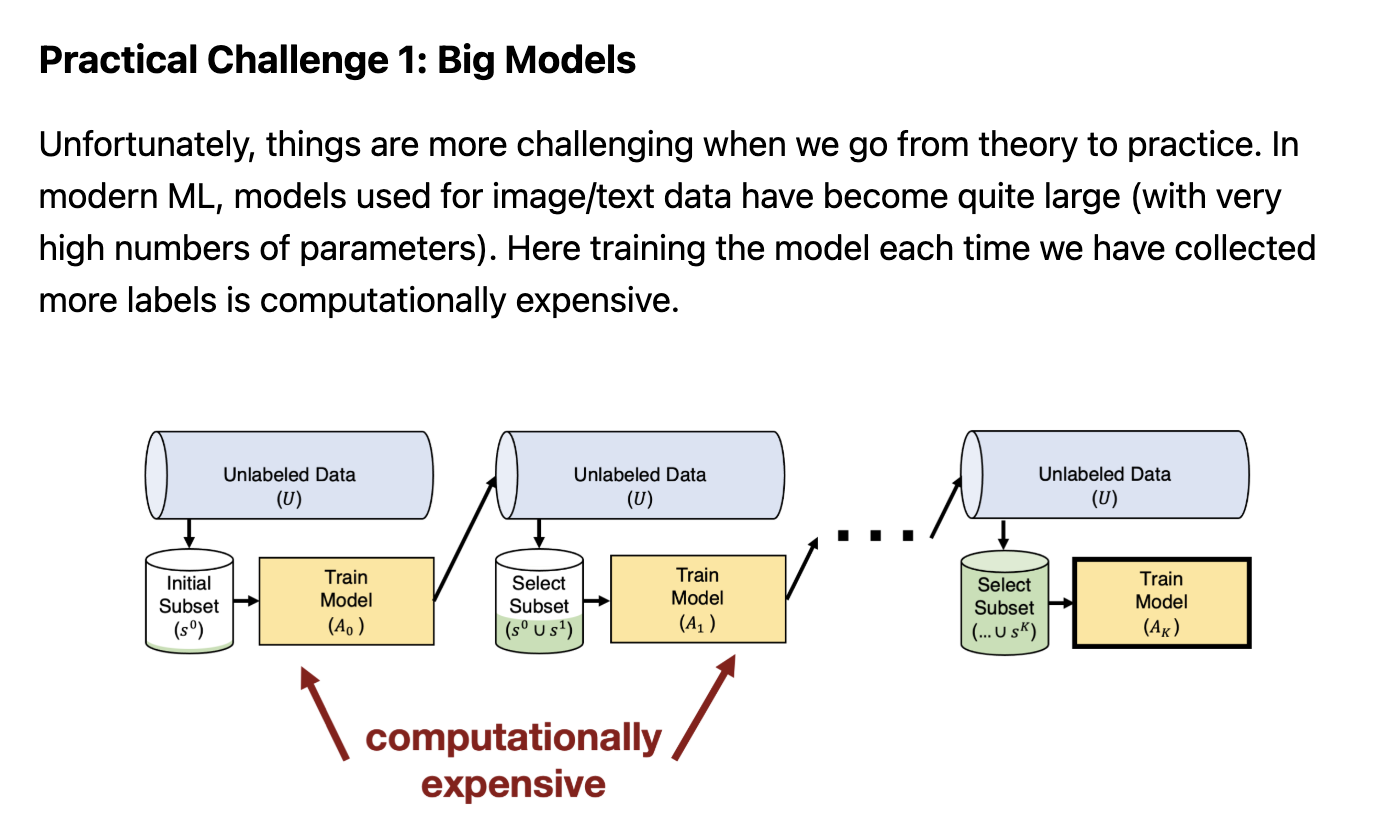
Key Benefits & Challenges
- Advantages
- Efficiency: Saves resources by focusing on the most impactful samples.
- Cost Reduction: Reduces the need to label large datasets.
- Challenges
- Determining which samples to label to maximize performance
- New emerging challenges in active learning during the era of deep learning.
- Applications
- Annotating medical data, where expert labeling is expensive (e.g., radiology images).
- Selecting rare concepts in large datasets using SEALS (Similarity search for Efficient Active Learning).
SEALS (Similarity search for Efficient Active )
Image Source: MIT- Growing or Compressing Datasets
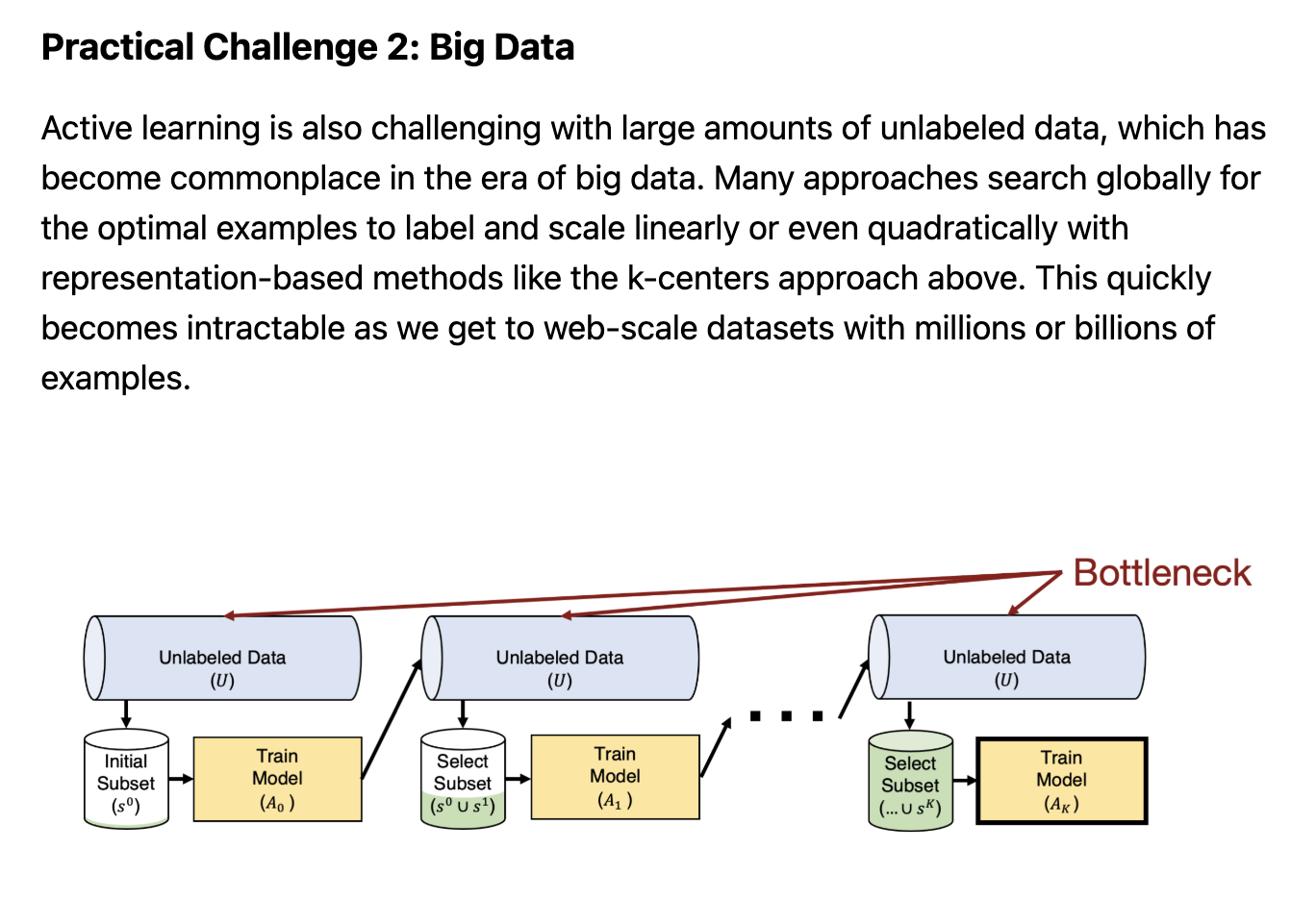
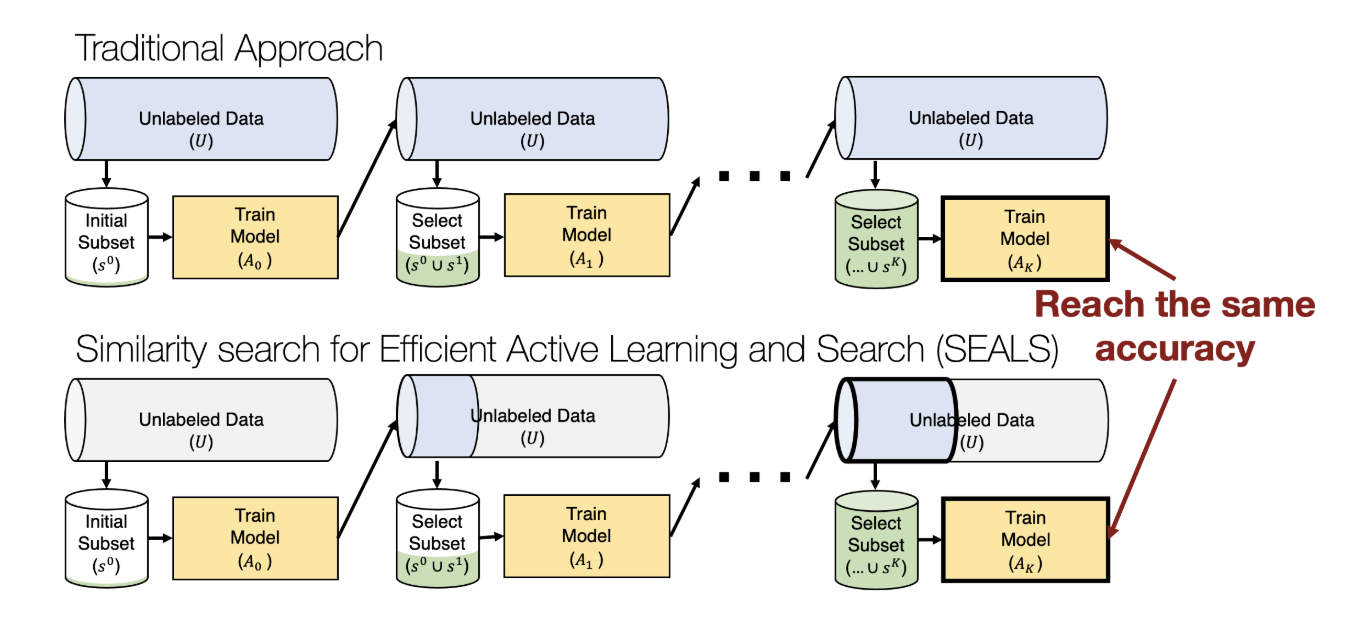
- SEALS starts the same way as conventional active learning, but uses similiarity ssearch such that it doesn’t need to run the deep learning system on all of the unlabeled data.
- Take newly labeled samples and find their neighbors.
- Procedures in SEAL
- Embedding Extraction
- Compute embeddings (vector representations) for all unlabeled data points using a pretrained model.
- Embeddings capture the semantic meaning of the data, making similarity searches more meaningful.
- Similar Matrix Computation
- Use locality-sensitive hashing (LSH) to create a fast approximate simliarity matrix.
- LSH groups similar embeddings together, enabling quick nearest neighbor searches.
- Candidate Selection
- Select the k-nearest neighbors of the labeled points based on the similiarity matrix.
- These neighbors form a smaller candidate pool for active learning.
- Uncertainty Scoring
- Apply uncertainty metrics (e.g., MaxEnt or ID) only to the candidate pool.
- Selecte the most uncertain points for labeling.
- Repeat
- After labeling the selected points, update the model and repeat the process.
- After labeling the selected points, update the model and repeat the process.
- Embedding Extraction
Dataset Pruning & Coreset Selection
Dataset pruning and coreset selection are techniques to reduce the size of datasets without compromising the performance of a machine learning model. These methods focus on identifying and retaining the most informative samples while discarding redundant or unhelpful data points.
- Active learning shows that not all examples hold the same value.
- Redundant samples yield less informative learning signals.
- We can analyze a large dataset to pinpoint the most informative training samples and eliminate the rest, a process known as dataset pruning or coreset selection.
Motivation for Dataset Pruning
- Redundancy in Datasets
- Large datasets often have redundant examples that provide minimal additional learning signal.
- For example, in CIFAR-10, thousands of images may convey similiar information about a class, sucha as “cats,” making many of them unnecessary for training.
- Computational Efficiency
- Training on large datasets is computationally expensive.
- Reducing the dataset size can speed up training without significantly degrading performance.
- Cost of Data Annotation
- In some domains, acquiring and annotating data (e.g., medical imaging) is expensive. Dataset pruning ensures that every labeled sample contributes meaningfully to model training.
- Avoiding Overfitting
- Pruning irrevant or noisy data reduces the risk of overfitting, especially in small or medium-sized datasets.
- Pruning irrevant or noisy data reduces the risk of overfitting, especially in small or medium-sized datasets.
Dataset Pruning and Scaling Laws
The problem with Power Laws
- Power Laws in Data Scaling
- Power laws describe how the performance of models scales with more data. While adding more data improves perforamnce, the returns diminish rapidly.
- For instance, going from 3% error to 2% error might require 10x more data.
- This creates a computational bottleneck for scaling, especially for large datasets or models.
- Implcation for Dataset Size
- Not all data contributes equally to improving performance.
- Redundant or “easy” samples often provide minimal gains, suggesting that selectively training on a subset of data could achieve comparable results.
Dataset Pruning and Informative Subsets
- The goal of dataset pruning is to reduce the size of the training set while preserving (or improving) the model’s performance.
- Focus on retaining the most informative examples that maximize the model’s learning.
- To reduce wastes of processing redunadant or low-value data.
- A smaller, high-quality dataset enables faster training and reduces memory requirements
- A smaller, high-quality dataset enables faster training and reduces memory requirements
Theoretical Framework for Dataset Pruning
- When to Keep Hard vs. Easy Samples
- Small Subset: If pruning agressively (keeping a small fraction of the data), prioritize "easy" samples.
- Easy samples provide foundational patterns that the model can generalize from.
- Large Subset: If keeping a larger fraction, focus on "hard" samples
- Hard samples challenge the model and force it to learn nuanced decision boundaries.
- Small Subset: If pruning agressively (keeping a small fraction of the data), prioritize "easy" samples.
- Statistical Insights
- Retaining only the hardest samples improves scaling laws when the initial dataset is large.
- Dataset pruning works better when we retain **a fixed fraction $f$ ** of the the hardest examples, rather than selecting samples randomly.
Dataset Pruning Methods
K-Means Clustering for Pruning
- Process:
- Use embeddings trained with self-supervised learning to cluster the dataset into groups.
- Define the “difficulty” of a sample by its distance to the nearest clsuter centroid
- Easy Samples: Close to the centroid; these are prototypical examples of the data.
- Hard Samples: Far from the cetnroid, these represent outliers or edge cases.
- Prune the dataset by retaining a mix of easy and hard samples, depending on the pruning strategy.
- Self-Supervised Learning
- Clustering works best with embeddings obtained from self-supervised learning because they capture general features without relying on labels.
- Using supervised embeddings risks grouping samples purely by class, which may miss nuanced relationships.
Hard vs. Easy Samples
- Top Row (Easy):
- Examples near the cluster centroids. These are representative, clear examples that the model can learn from quickly.
- Bottom Row (Hard):
- Edge cases far from the centroids. These challenge the model and help refine decision boundaries.
- Edge cases far from the centroids. These challenge the model and help refine decision boundaries.
Effectiveness:
- On ImageNet, it was shown that:
- Retaining only 80% of the training samples resulted in near-original performance.
- This highlights the redundancy in the dataset and the potential for pruning.
Leave a comment