
Day104 Deep Learning Lecture Review - Lecture 19
Data-Centric AI: Label Noise, Selection Bias, Data Leakage, and Error Analysis for Model Improvement (Subgroup Errors)
Model-centric AI focuses on algorithmic elements like training techniques and regularization, relying on a dataset that is often static. However, real-world datasets are dynamic. In contrast, data-centric AI emphasizes the systematic enhancement of data to create superior AI systems, prioritizing the data itself over the specific models used.
Label Noise
- Many Datasets Have Label Noise
- Many datasets (e.g., ImageNet, CIFAR-100) contain mislabeled samples. For example, CIFAR-100 has 6% label errors.
- Some label errors can be corrected, while others arise from multi-label inputs, out-of-distribution data, etc.
- Impact:
- Small amounts of label noise often do not significantly impact learning.
- However, label noise in test sets can lead to misleading performance metrics.
-
Test Set Noise: Models like ResNet-18 can outperform larger models like ResNet-50 in the presence of noisy labels, highlighting potential overfitting to noise.
-
Correcting Errors
- Identifying and correcting label errors can improve performance and make evaluation more accurate.
- Remember to version the datasets. Correcting errors creates a new version of the dataset.
Techniques to Address Label Noise
-
Confident Learning:
- Identifies likely label errors using predicted probabilities and observed noisy labels.
- Does not require any guaranteed uncorrupted labels.
- Non-iterative and applicable to multi-class datasets.
- Example: Detecting label errors in ImageNet in 3 minutes.
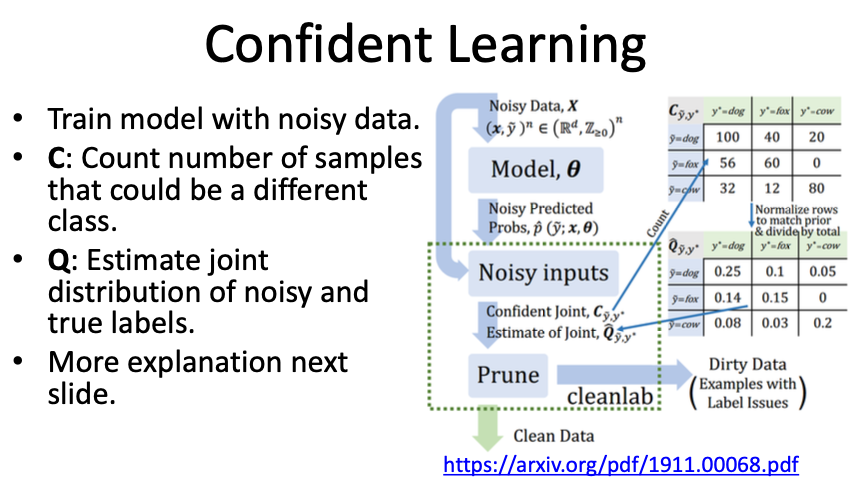
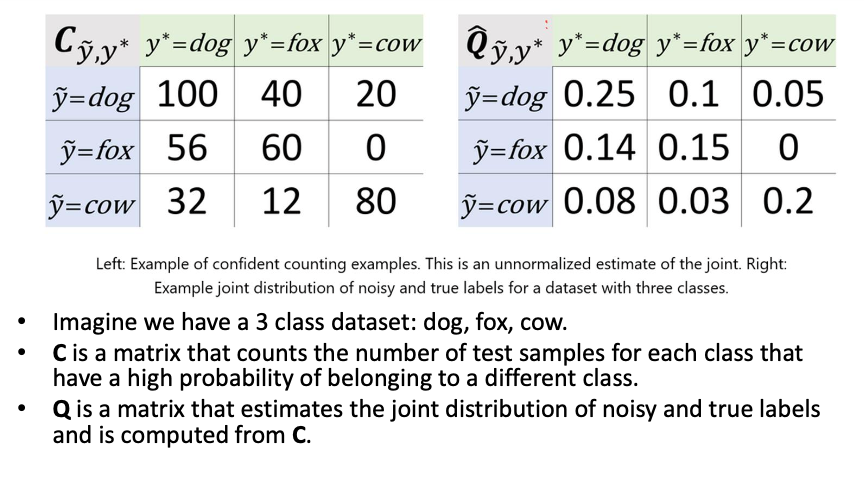

- Using the Q Matrix
- Multiply Q by the number of examples.
- If there are 100 examples in this case, then there would be 10 images labeled as dogs that are predicted actually to be foxes.
- Identify the 10 images labeled as dogs with the highest probability of belonging to the fox class.
- Repeat this process for all non-diagonal entries in the matrix.
- Confident Learning and Cross-Validation
- The process outlined applies solely to the test dataset.
- To identify label errors in the training dataset, utilize cross-validation.
-
Using Embeddings
- Train a strong self-supervised model (e.g., DinoV2).
- Cluster embeddings and inspect outliers for potential errors.
- Human validation is often needed to confirm errors.
- For class $k$, identify outliers that have a significant distance from the nearest cluster centroid for that class.
- For outliers, determine if they are nearer to a centroid from a different class.
- If they are closer to a different class, review these samples for potential label errors with the assistance of a human expert.
-
Human-validation of Label Errors
- Why It’s Needed:
- Methods like confident learning or embedding-based clustering are not 100% accurate.
- Human review ensures ambiguous cases are resolved accurately.
- Best Practices:
- Use multiple annotators to check each flagged sample.
- Resolve disagreements with a consensus review.
- Why It’s Needed:
Selection Bias
Deep learning systems can perform exceptionally well on test data that aligns with the training distribution; however, dataset bias remains a significant challenge. Addressing this issue using more data might not be practical, as some events are inherently rare and challenging to extract.
Data Leakage
When the test set is contaminated with training data, leading to inflated performance metrics.
- Write A Lot of Tests to Mitigate Leakage
- We should have a lot of tests to mitigate leakage and ensure our splits are not contaminated.
- Try to ensure all data is unique before splitting.
- Examples:
- Cancer detection systems should ensure that individual patient data is not included in the training or test sets. The test set should be as independent from the training set as possible.
- Otherwise, we may inflate performance.
- Slightly modified duplicates of training data are present in the test set.
- Cancer detection systems should ensure that individual patient data is not included in the training or test sets. The test set should be as independent from the training set as possible.
- Statistics Are Not Sufficient
- While accuracy and other summary statistics are helpful, they obscure many facets of performance and do not indicate how to enhance the model.
- We must think deeply about what we are trying to achieve and design appropriate metrics.

-
One Statistic?
-
Due to label bias, one statistic can create the impression that a model is performing well when, in fact, it isn’t.
-
We must define “ chance “ and ensure that the model outperforms merely predicting the most likely category.
-
Reporting only average performance can under-represent severe failure cases for rare examples and subpopulations.
-
-
Confusion Matrix
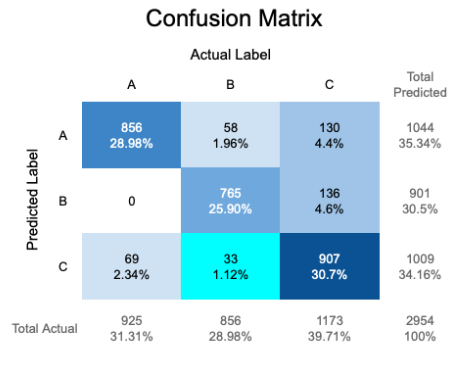
- Use a confusion matrix for classification and mutually exclusive classes. A confusion matrix provides a comprehensive overview of a classification model’s performance by showing true positives, false positives, true negatives, and false negatives.
- However, it does not suffice for subgroups. Alternative measures, such as F1 scores or precision-recall curves, should be considered for datasets that contain overlapping classes or subgroup dependencies.
- The mean of the normalized diagonal is the mean per class accuracy.
-
Stratified Performance
- We need to stratify performance across sub-groups (i.e., data slices)
- Compute performance for each sub-group
- Class labels
- Sub-population
- Demographics: race, sex, blood type, geography, etc.
- Type of camera/scanner
- Time of day
- Background environment
- What’s the accuracy of recognizing camels in the forest
- Compute sub-group performance to overall performance.
- Ideally use hypothesis testing and/or confidence intervals to compare performance for each sub-group to overall performance.
- Ideally use hypothesis testing and/or confidence intervals to compare performance for each sub-group to overall performance.
Finding and Addressing Subgroup Failures
What if we do not have the relevant variables or do not know where things are going wrong? How can we identify high-error subgroups?
- Identifying High-Error Subgroups
- Sort examples from the validation dataset based on their loss values, focus on those with the highest loss where the model’s predictions are least accurate.
- Use clustering on the embeddings of test samples that have high loss to uncover clusters that share common themes.
- Inspect the clusters to understand whether certain attributes (e.g., lighting conditions, background) lead to systematic errors.
- Visualizing Model Errors
- Visualizing errors helps to uncover the reasons for failures, whether they are due to
- Label Noise
- Ambiguous or out-of-distribution(OOD) samples
- Artifacts in the data
- Visualizing errors helps to uncover the reasons for failures, whether they are due to
-
Inspect the Errors
- Errors from label noise $\rightarrow$ correct the error.
- Errors from artifacts or low-quality samples $\rightarrow$ decide whether to remove them from the training set or retain them for robustness teating.
- Errors from OOD samples $\rightarrow$ save these for future model fine-tuning or OOD detection tasks.
- Errors due to ontology problems $\rightarrow$ reconsider ontology or use multi-label classification.
- Otherwise, errors could indicate subgroups we need to handle.
Revisiting Metrics
- Why Standard Metrics Are Insufficient
- Metrics like accuracy or F1-score often fail to highlight severe performance issues in subgroups or rare events.
- A single high-level metric may mislead stakeholders into believing the model is robust.
- New Metrics for Subgroups
- Subgroup-Specific Metrics
- Compute accuracy, precision, or recall for each subgroup independently.
- Compare subgroup performance to the overall meric.
- Confidence Intervals and Hypothesis Testing
- Use statistical methods to validate whether differences between subgroups are significant.
- Use statistical methods to validate whether differences between subgroups are significant.
- Subgroup-Specific Metrics
Improving Sub-Group Performance
Techniques
-
Increasing Model Capacity
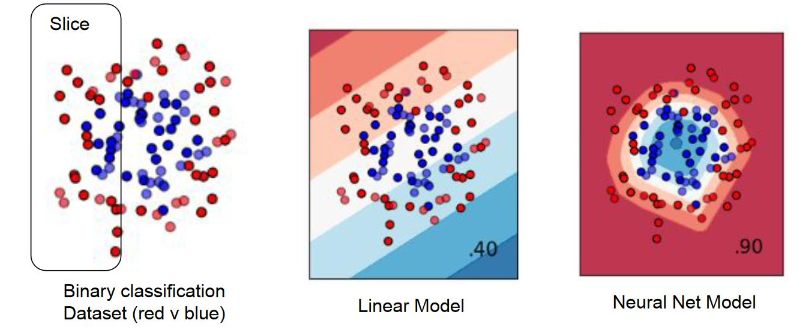
- Larger models are more capable of capturing complex patterns and performing well on diverse subgroups.
- However, this approach increases computational costs.
-
Oversampling Underrepresented Subgroups
- Increase the representation of underrepresented subgroups in the training data.
- Methods like SMOTE can be used to synthetically generate new samples for these subroups.
- Obtaining More Data from a Subgroup
- We can use neural network scaling laws to keep most of the dataset while creating several smaller datasets with less data for the subgroup that isn’t performing well.
- Check how well the subgroup performs for each dataset size, making sure that only the subgroup’s data is reduced.
- Use neural network scaling laws to predict how much better the model's performance for that subgroup could be with more data.
- It’s often tough to get additional data from subgroups.
-
Conditioning the Model on Subgroup Information
-
If the model cannot infer the subgroup from the raw inputs, but we have the variable available, we could try conditioning the model on the subgroup.
-
Use subgroup attributes (e.g., demographics, environment type) as additional inputs to guide the model.
-
Techniques include:
-
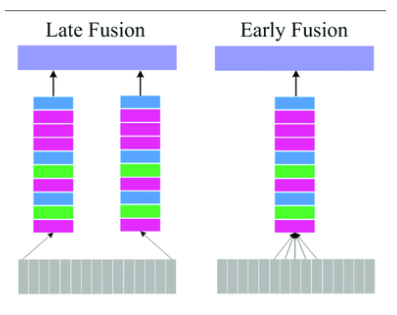
Early Fusion: Concatenating subgroup attributes with input features.
- $\text{Prob} (C=k \ \vert \ \textbf{X}, G=g)$
- If the dimensionality of $\textbf{X}$ is low, we may simply concatenate an embedding that captures the status of $G$.
-
Late Fusion: Processing input and subgroup features independently before combining them at a higher layer.
- Adapted from Peng, Min et al., Dual Temporal Scale Convolutional Neural Network for Micro-Expression Recognition. Frontiers in Psychology. 8.
-
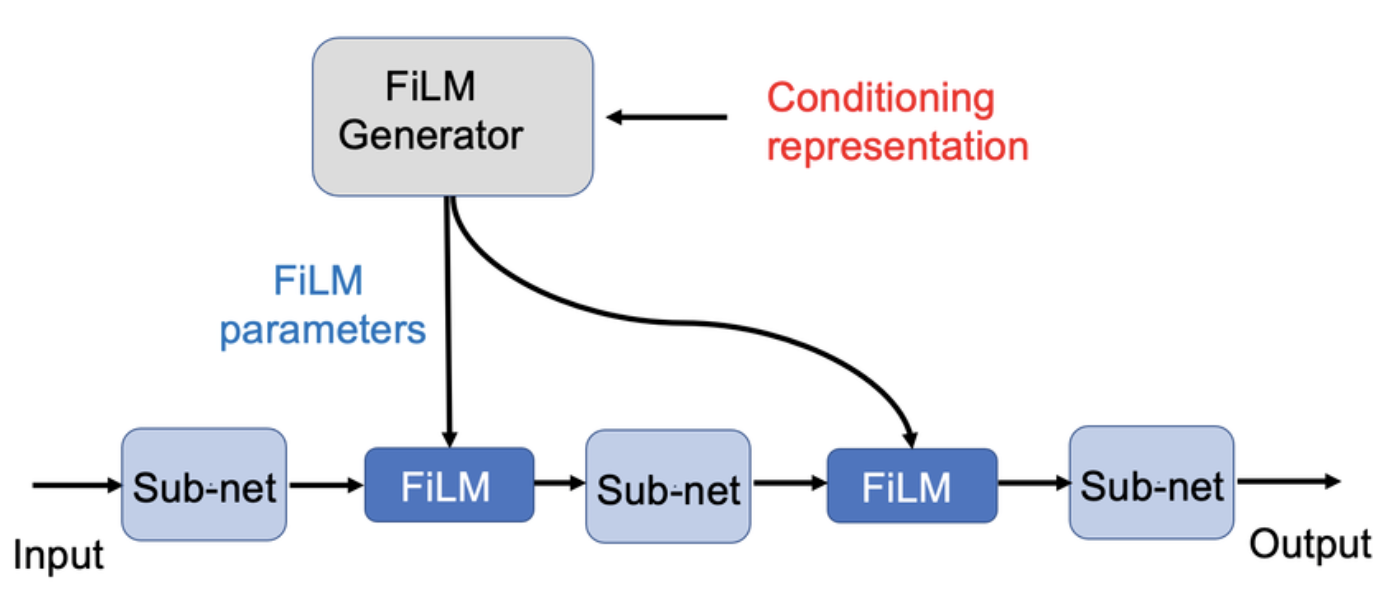
FiLM(Feature-wise Linear Modulation): Applying subgroup-specific scaling and shifting to model features.
-
Adapted from Perez et al., ‘FiLM: Visual Reasoning with a General Conditioning Layer’, 2018.
-
-
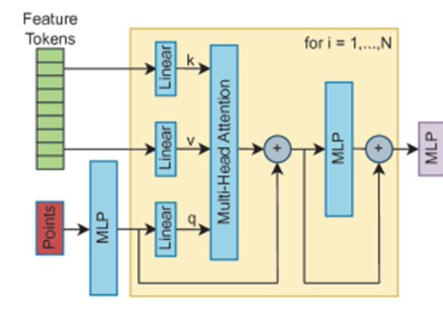
Cross-Attention: Modifying the attention mechanism to focus on subgroup-relevant patterns.
-
Adapted from Vaswani et al., ‘Attention Is All You Need’, 2017.
-
-
-
Splitting Datasets
- Before Splitting Data
- Clean the data:
- Remove label errors and analyze outliers to ensure high-quality splits.
- Understand stand objectives:
- Define the goals of the study and establish preliminary evaluation metrics.
- Clean the data:
- Splitting Strategy
- Train, Validation, and Test Sets
- Divide the data into three main subsets:
- Train Set: For model training
- Validation/Calibration Set: For tuning hyperparameters and evaluating performance during development.
- Test Set: For final model evaluation.
- Focus on the test set first
- Design the test set to ensure there are enough samples in each subset to calculate meaningful statistics.
- Divide the data into three main subsets:
- Multiple Test Sets
- Use multiple test sets for different evaluation scenarios (e.g., general performance, edge cases)
- Use multiple test sets for different evaluation scenarios (e.g., general performance, edge cases)
- Train, Validation, and Test Sets
Golden Test Sets
A quarantined dataset used exclusively for final evaluation. It is untouched during model development.
- Required in fields like healthcare (e.g., FDA validation)
- Often curated by domain experts (e.g., physicians for medical datasets.)
Leave a comment