
Day47 ML Review - Data Preprocessing (1)
Handling Missing Data - Eliminating and Imputing & Estimators API
Preprocessing datasets is a critical step in machine learning and data analysis, as it prepares raw data for modeling by cleaning, transforming, and organizing it. Proper preprocessing can significantly improve the performance of a model. Here’s a step-by-step guide to the common preprocessing steps:
Dealing with Missing Data
We typically see missing values as blank spaces in our data table or placeholder strings such as NaN, which stands for “not a number,” or NULL ( a commonly used indicator of unknown values in relational databases). As most computational tools cannot handle these missing values, we must take care of them before proceeding with further analyses.
We can use the isnull method to return a DataFrame with Boolean values that indicate whether a cell contains a numeric value (False) or if data is missing (True). Using the sum method, we can return the number of missing values per column as follows. This way, we can count the number of missing values per column.
import pandas as pd
df = pd.read_csv(df)
df.isnull().sum()
Eliminating Missing Values
If a dataset has many missing values in its rows or columns, the most straightforward approach may be to remove those rows or columns. Rows with missing values can quickly be dropped via the dropna method.
df.dropna(axis=0)
Similarly, we can drop columns with at least one NaN in any row by setting the axis argument to 1.
df.dropna(axis=1)
The dropna method supports several additional parameters that can be useful, as follows.
# only drop rows where all columns all NaN
df.dropna(how='all')
# drop rows that have fewer than 4 real values
df.dropna(thresh=4)
# only drop rows where NaN appears in specific columns (here: 'C')
df.dropna(subset=['C'])
Although removing all NaN columns looks very convenient, it also comes with certain disadvantages. For example, we may need to remove more samples, making a reliable analysis impossible. Or, if we remove too many feature columns, we risk losing valuable information that our classifier needs to discriminate between classes.
Imputing Missing Values
In another way, we can use different interpolation techniques to estimate the missing values from the other training examples in our dataset.
- Mean/Median/Mode Imputation: Replace missing values with the column’s mean, median, or mode.
- Forward/Backward Fill: Use the previous or next value in the column to fill in the missing values (mainly for time series data).
- Interpolation: Estimate missing values using interpolation methods (practical for time series data).
- Model-Based Imputation: Utilize machine learning models to predict and fill in missing values.
For example, we can use mean imputation to replace the missing value with the mean value of the entire feature column. A convenient way to achieve this is by using the SimpleImputer class from scikit-learn as follows.
from sklearn.impute import SimpleImputer
import numpy as np
imr = SimpleImputer(missing_values=np.nan, strategy='mean')
imr = imr.fit(df.values)
imputed_data = imr.transform(df.values)
In our data manipulation process, we addressed missing values NaN by filling them with the mean of each feature column. Additionally, we discussed alternatives in strategies parameters, such as using the median or most_frequent for imputation. The most_frequent option is handy when dealing with categorical feature values, such as columns representing color names (e.g., red, green, and blue).
Another approach to address missing values is to utilize Pandas’ fillna method and specify an imputation method as an argument. For instance, within the DataFrame object in Pandas, we can seamlessly implement mean imputation with the following command:
df.fillna(df.mean())
Side Note
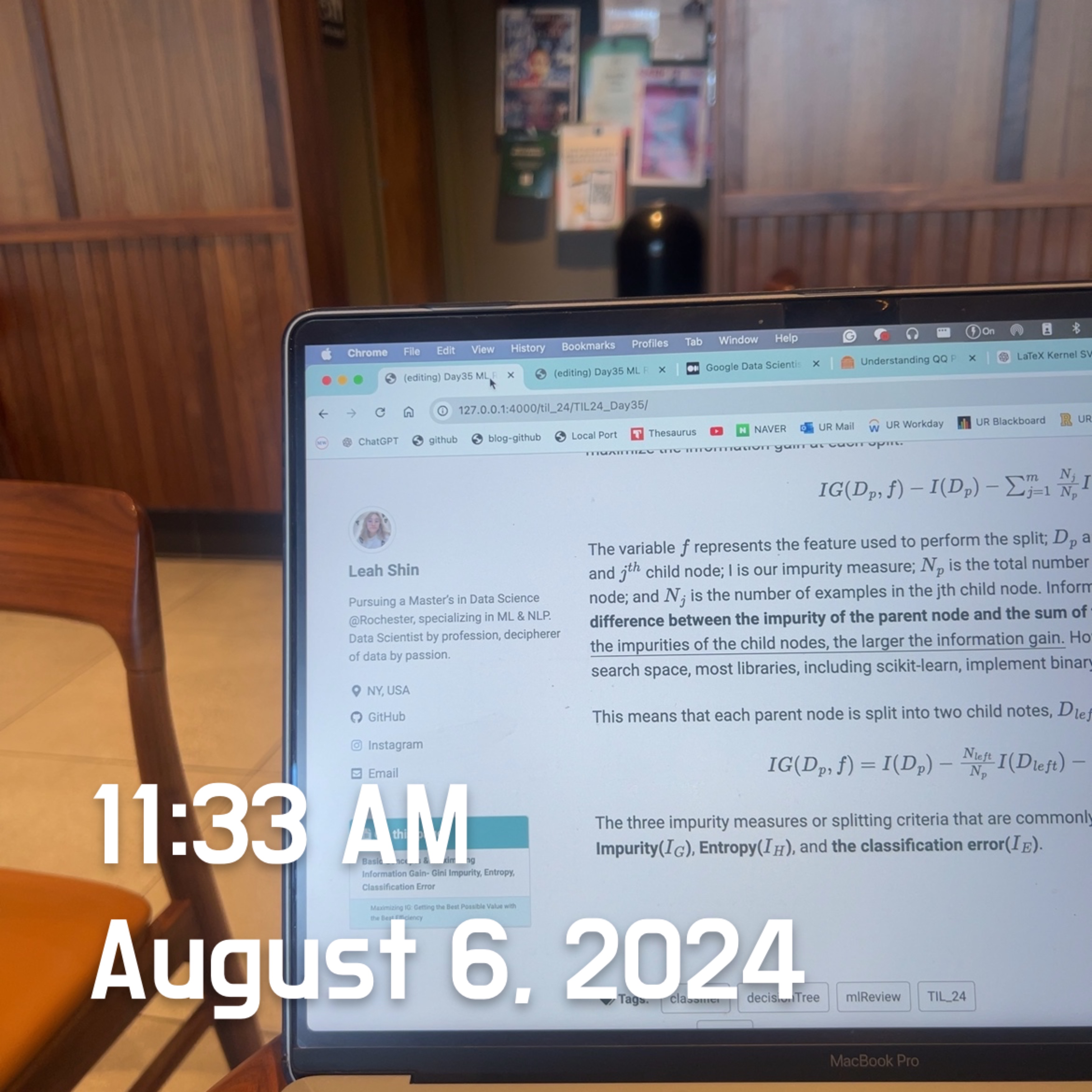
The SiimpleImputer class from scikit-learn belongs to the so-called transformer classes used for data transformation. The two essential methods for these estimators are fit and transform. The fit method is used to learn the parameters from the training data, while the transform method uses those parameters to transform the data. Any data array that needs to be transformed must have the same number of features as the data array used to fit the model.
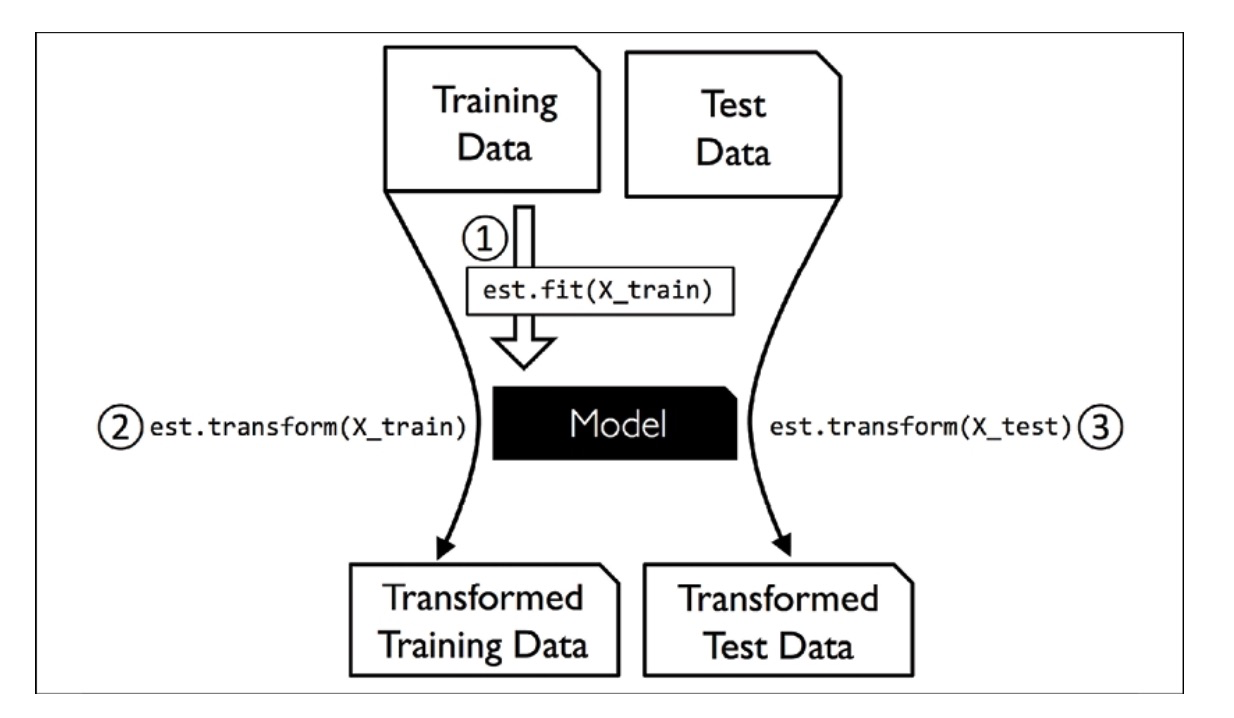
The various classifiers in scikit-learn are considered estimators and have an API similar to the transformer class. Estimators have a predict method and can also have a transform method. When training these estimators for classification, we use the fit method to learn the model’s parameters. In supervised learning tasks, we provide class labels in addition to fitting the model, which enables us to make predictions about new, unlabeled data examples using the predict method.
Leave a comment