
Day55 ML Review - Pipeline
Key Concepts and Example Code with Scikit-learn
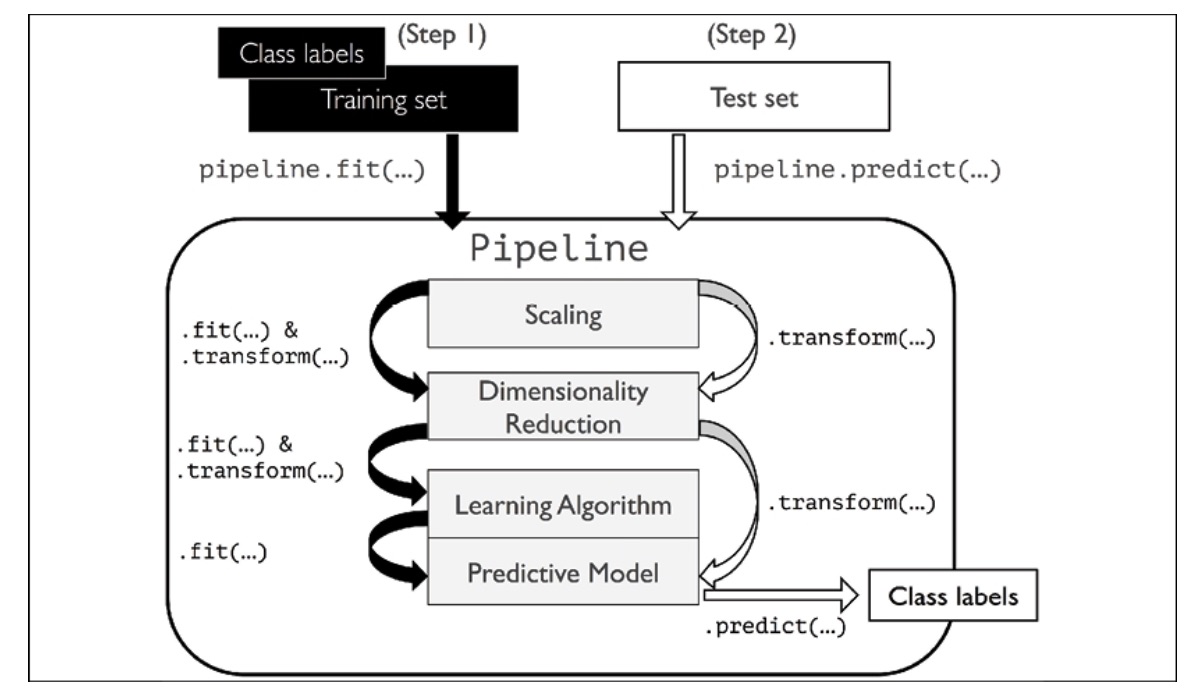
When dealing with several datasets, utilizing the parameters acquired from fitting the training data to standardize and compress fresh data is crucial. This process entails implementing these parameters to instances in a distinct test dataset. The scikit-learn
Pipelineclass enables us to train a model containing any number of transformation stages and use it to generate predictions for new data.
Loading the Dataset
We will begin by directly implementing the Breast Cancer Wisconsin dataset from the UCI website and incorporating it into a pipeline.
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/' 'machine-learning-databases' '/breast-cancer-wisconsin/wdbc.data', header=None)
First, we will collect the 30 features and organize them into a NumPy array called X. Next, we will use a LabelEncoder object to convert the class labels, originally represented as 'M' and 'B,' into integer values. After encoding the class labels (diagnosis) into an array called y, the malignant tumors ('M') will be represented as class 1, and the benign tumors will be represented as class 0.
from sklearn.preprocessing import LabelEncoder
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transformer(y)
le.classes_array(['B', 'M'], dtype=object)
Start with dividing the dataset into a separate training dataset(80 percent of the data) and a separate test dataset(20 percent of the data).
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=1)
Combining Transformers and Estimators in a Pipeline
The features in the Breast Cancer Wisconsin dataset are measured using different scales. Standardizing the columns before using them in a linear classifier like logistic regression is essential. Additionally, we aim to reduce the dimensionality of the data from the original 30 dimensions to a two-dimensional subspace using principal component analysis (PCA).
Instead of going through the model fitting and data transformation steps for the training and test datasets separately, we can chain the Standard-Scaler, PCA, and LogisticRegression objects in a pipeline.
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
pipe_lr = make_pipeline(StandardScaler(), PCA(n_components=2), LogisticRegression(random_state=1, solver='lbfgs'))
pipe_lr.fit(X_train, y_train)
y_pred = pipe_lr.predict(X_test)
print('Test Accuracy: %.3f' % pipe_lr.score(X_test, y_test))
The make_pipeline function in scikit-learn allows you to create a data processing and model training workflow by chaining together multiple transformers and an estimator. These transformers can be used to preprocess the data, and the estimator is the model that is trained on the preprocessed data.
When we call the fit method on the Pipeline, the data goes through each transformer in sequence, undergoing any necessary preprocessing at each step, before finally being used to train the estimator.
After fitting the pipeline, you can use the predictmethod to make predictions on new data. The data goes through the same preprocessing steps before being fed into the trained estimator, which then makes predictions based on the preprocessed data.
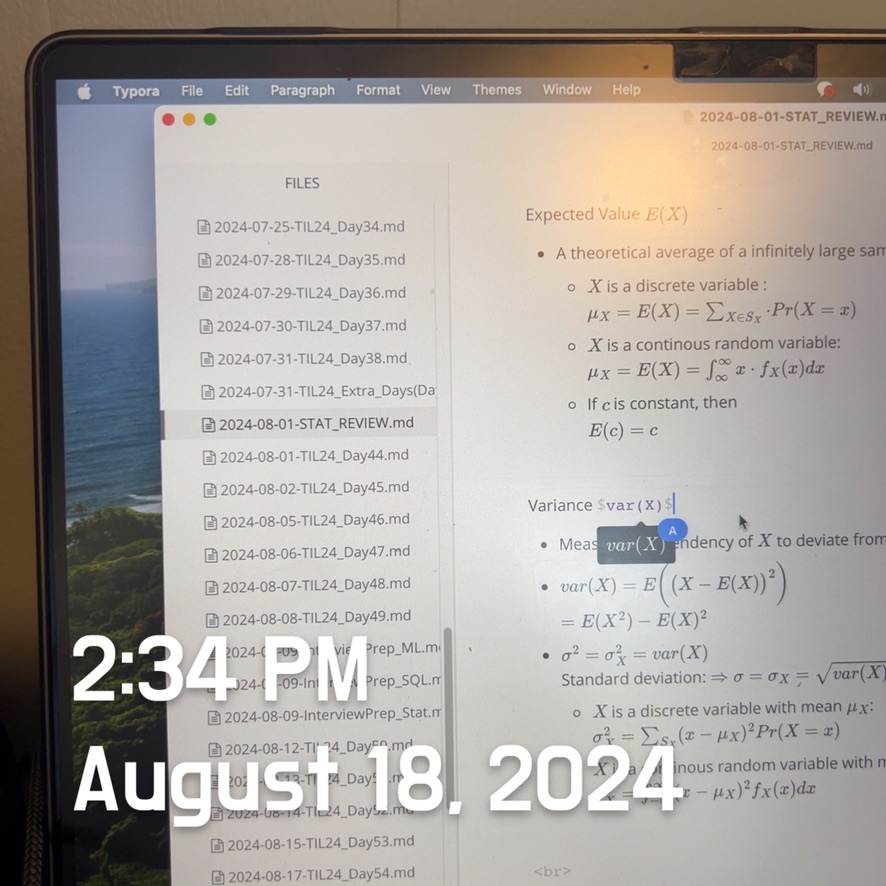
Leave a comment