
Day70 DL Review - Transformer
Transformer Architecture, How the Models Are Different, and Q,K,V in Self-Attention

Source: IBM - Transformers
A Transformer is a neural network architecture specifically crafted for sequential data processing. Unlike traditional models like Recurrent Neural Networks (RNNs), it analyzes the entire sequence concurrently and employs a self-attention mechanism to understand relationships among various parts of the sequence. The Transformer architecture was first introduced in the 2017 paper “Attention is All You Need” by Vaswani et al., and it has since laid the groundwork for numerous advanced models in natural language processing (NLP), including BERT, GPT, and T5.
Transformer Architecture
- Self-Attention Mechanism
- Self-attention, or scaled dot-product attention, is fundamental to the Transformer model. It enables each element in the input sequence to interact with every other element. Consequently, every token—whether a word, subword, or character—can directly obtain information about any other token, thereby efficiently capturing relationships between far-apart segments of the input.
- The self-attention mechanism works by calculating a weighted sum of the values (input representations), where the weights (attention scores) are computed based on the relationships (similarity) between each pair of elements in the sequence.
-
Multi-Head Attention: In multi-head attention, the self-attention mechanism operates in parallel across several heads, each focusing on different aspects of the relationships among elements. The outputs from these attention heads are subsequently merged, enabling the model to grasp more complex patterns.
-
Positional Encoding: Unlike RNNs, which process sequences one at a time, transformers simultaneously handle the entire input sequence. Positional encodings are incorporated into the input embeddings to give the model to grasp the relative positions of tokens within the sequence.
-
Feed-Forward Neural Network (FFN): A feed-forward neural network processes each token’s representation individually, following the attention layers. This enables additional refinement of the information gathered by the attention mechanism. The feed-forward network consists of two fully connected layers with a non-linear activation function (usually ReLU) in between.
-
Layer Normalization: Every Transformer layer is succeeded by layer normalization, which stabilizes and accelerates training by normalizing the inputs for each layer.
- Residual Connections: The Transformer employs residual connections to facilitate training and prevent vanishing gradients. These connections bypass the attention and feed-forward layers, directly adding the layer’s input to its output. This mechanism enhances the efficient flow of information throughout the network.
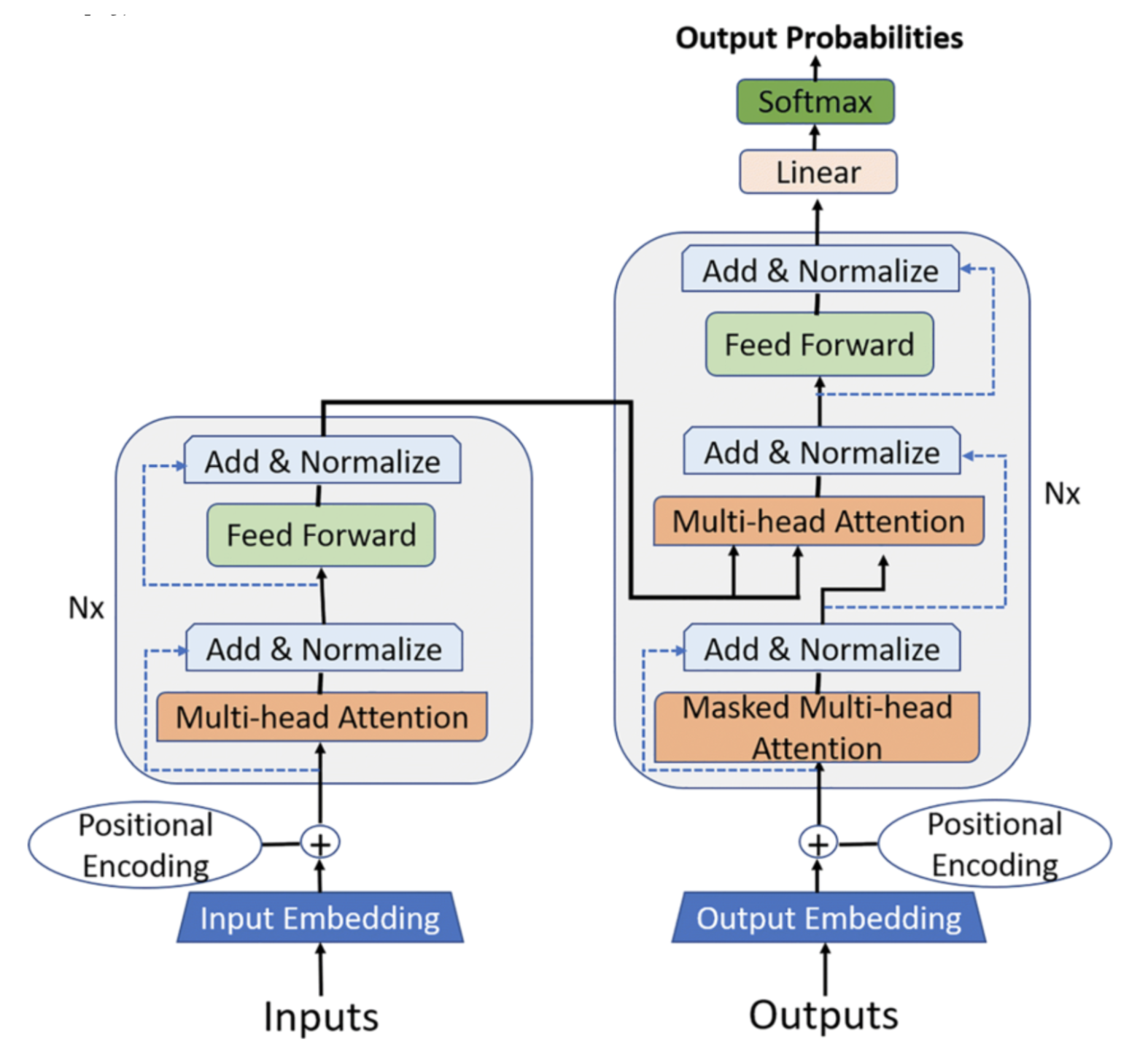
Image Source: [Nassiri, K., & Akhloufi, M. A. (2022). Transformer models used for text-based question-answering systems. Applied Intelligence, 53(1-2).
How Transformer Models Are Different
The transformer model’s key innovation lies in its independence from recurrent neural networks (RNNs) and convolutional neural networks (CNNs), which have notable limitations. Unlike these models, transformers handle input sequences simultaneously, resulting in increased efficiency for both training and inference; simply adding more GPUs won’t suffice for speeding up processes. Moreover, transformer models require less training time compared to older recurrent neural network architectures like long short-term memory (LSTM).
Two Big Innovations
Transformer models offer two primary innovations. Consider these two innovations in the context of text prediction.
-
Positional Encoding: Instead of looking at each word in the order it appears in a sentence, a unique number is assigned to each word. This provides information about the position of each token (parts of the input, such as words or subword pieces in NLP) in the sequence, allowing the model to consider the sequence’s sequential information.
-
Self-Attention: Attention is a process that assigns weights to each word in a sentence based on its relationship to the others, enabling the model to predict the sequence of words likely to follow. This knowledge is acquired over time as the model processes extensive data. The self-attention mechanism enables every word to connect with all others within the sequence simultaneously, assessing their relevance to the current token. Thus, it’s fair to say that machine learning models can “learn” grammar rules through the statistical patterns of word usage in language.
How Do Transformer Models Work?
Transformer models process input data—whether sequences of tokens or structured information—through multiple layers equipped with self-attention mechanisms and feedforward neural networks. The fundamental concept of transformer models can be outlined in several essential steps.
Suppose you want to translate an English sentence into French. You would follow these steps to achieve this with a transformer model.
- Input embeddings: The input sentence is first transformed into numerical representations called embeddings. These capture the semantic meaning of the tokens in the input sequence. For sequences of words, these embeddings can be learned during training or obtained from pre-trained word embeddings.
- Positional encoding: Positional encoding is typically introduced as a set of additional values or vectors added to the token embeddings before feeding them into the transformer model. These positional encodings have specific patterns that encode the position information.
- Multi-head attention: Self-attention operates in multiple “attention heads” to capture different types of relationships between tokens. Softmax functions, an activation function, are used to calculate attention weights in the self-attention mechanism.
- Layer normalization and residual connections: The model uses layer normalization and residual connections to stabilize and speed up training.
- Feedforward neural networks: The output of the self-attention layer is passed through feedforward layers. These networks apply non-linear transformations to the token representations, allowing the model to capture complex patterns and relationships in the data.
- Stacked layers: Transformers typically consist of multiple layers stacked on each other. Each layer processes the previous layer’s output, gradually refining the representations. Stacking various layers enables the model to capture hierarchical and abstract features in the data.
- Output layer: In sequence-to-sequence tasks like neural machine translation, a separate decoder module can be added to the encoder to generate the output sequence.
- Training: Transformer models are trained using supervised learning, where they learn to minimize a loss function that quantifies the difference between the model’s predictions and the ground truth for the given task. Training typically involves optimization techniques like Adam or stochastic gradient descent (SGD).
- Inference: After training, the model can infer new data. During inference, the input sequence is passed through the pre-trained model, and the model generates predictions or representations for the given task.
Q, K, V in Self-Attention
The self-attention mechanism is crucial for understanding relationships among various tokens in a sequence. It depends on three main components: Queries (Q), Keys (K), and Values (V). These components compute the relevance or attention score between sequence elements, enabling the model to concentrate on significant aspects of the input while addressing other segments.
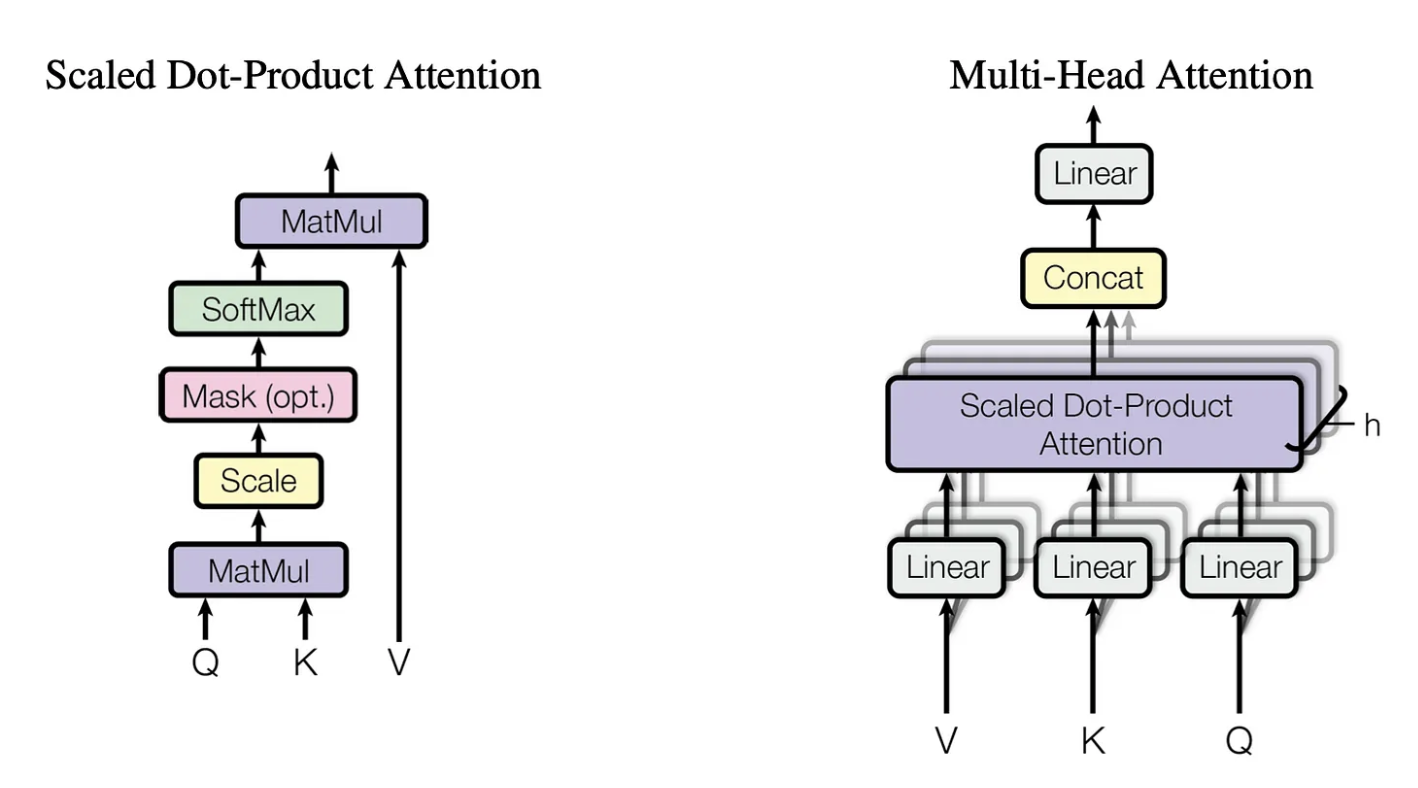
Image Source : [Vaswani, A., et el(2017). Attention is All You Need in Advances in Neural Information Processing Systems (NeurIPS) (pp. 5998-6008)]
1. Input Representation
Each token (word, subword, etc.) in the input sequence is first converted into a vector (embedding). These vectors represent the token in a continuous space and form the input to the Transformer model.
2. Linear Projections for Q, K, and V
For each input token, three vectors are computed through linear transformations:
- Query (Q): Captures what this token is “asking” or looking for in other tokens.
- Key (K): Represents how much information other tokens contain relevant to the query. It is used to measure the similarity between tokens.
- Value (V): Contains the actual information of the token. The “content” will be weighted based on the attention scores computed from the query and key.
These projections are learned during the model’s training. They are generated by multiplying the input embedding by three different weight matrices $W_Q, W_K, W_V$, which results in the query, key, and value vectors.
$Q = XW_Q, \quad K = XW_K, \quad V = XW_V$
Where:
- $X$ is the input embedding.
- $W_Q, W_K, W_V$ are learned weight matrices for the queries, keys, and values.
3. Attention Mechanism (Scaled Dot-Product Attention)
The core of the Transformer’s self-attention mechanism involves calculating the attention scores between different tokens in the sequence based on the dot product of the Query and Key vectors. Here’s how it works:
- Similarity Calculation: For each token in the input sequence, the dot product of its query vector (Q) is computed with the key vector (K) of all other tokens in the sequence (including itself). This gives a similarity score that indicates how much attention one token should pay to another.
$\text{Attention Score} = Q \cdot K^\top$ - Scaling: To avoid tremendous values from the dot product when working with high-dimensional vectors, the scores are scaled by dividing by the square root of the dimension of the critical vectors $d_k$. This ensures more stable gradients during training.
$\text{Scaled Attention Score} = \frac{Q \cdot K^\top}{\sqrt{d_k}}$ - Softmax: The scaled scores are passed through a softmax function to convert them into probabilities. This gives the attention weights that indicate how much each token should attend to other tokens. The softmax ensures that the attention weights for each query sum to 1.
$\text{Attention Weights} = \text{softmax}\left(\frac{Q \cdot K^\top}{\sqrt{d_k}}\right)$ - Weighted Sum of Values: The attention weights are then used to compute a weighted sum of the value vectors (V) for each token. This gives the output for each token, where the contribution of other tokens is weighted by how much attention is paid to them.
$\text{Output} = \sum (\text{Attention Weights} \times V)$
4. Multi-Head Attention
To capture different types of relationships between tokens, the Transformer uses multi-head attention. Instead of using just one set of queries, keys, and values, the model performs the self-attention mechanism multiple times in parallel with different learned projections (each set is called a “head”).
- The input is projected into multiple Q, K, and V sets (one for each attention head).
- Each head performs the self-attention mechanism independently, resulting in different attention outputs.
- The outputs of all the heads are then concatenated and passed through a linear transformation to get the final output.
Multi-head attention allows the model to focus on different parts of the input simultaneously and learn more complex relationships.
5. Putting It All Together
- The final output of the multi-head attention layer is passed through a feed-forward neural network.
- Positional encodings are added to the inputs to ensure that the model understands the order of tokens, as Transformers do not inherently process sequences in a left-to-right or sequential manner.
Example Walkthrough:
Let’s take an example of a sentence: “The cat chased the mouse”.
- Each word in the sentence is embedded into a vector.
- For the word “chased”, its query vector is compared (via dot product) to the key vectors of all other words to calculate attention scores.
- The attention scores determine how much “chased” should attend to other words like “cat” and “mouse”.
- The final output for “chased” is a weighted combination of the value vectors of “cat”, “chased”, and “mouse”, based on the attention weights.
Leave a comment