
Day74 Deep Learning Lecture Review - Lecture 6
Large Language Model - BERT, GPT, and GPT-2, 3 & 4
BERT
BERT, which stands for Bidirectional Encoder Representations from Transformers, is a groundbreaking deep learning model introduced by Google in 2018. It is primarily designed for Natural Language Processing (NLP) tasks and has revolutionized how machines understand and generate human language.
1. Key Features
- BERT takes a chunk of text (sentences, paragraphs) as input and produces an embedding for downstream tasks.
- Can fine-tune BERT and variants of BERT for classification or regression tasks.
- Can use embeddings in multi-modal systems, e.g., Visual Question Answering.
-
Bidirectional Context Understanding: BERT reads text in both directions (left-to-right and right-to-left) using the Transformer architecture, capturing a deeper, more nuanced understanding of words in context, unlike traditional models like GPT, which read text in a single direction.
-
Transformer Architecture: BERT is based on the Transformer model, which uses self-attention mechanisms to weigh the importance of each word and every other word in a sentence. This allows BERT to capture complex relationships between words. (But it is just a transformer's encoder stack.)
-
Pre-trained on Large Corpora: BERT is pre-trained on vast amounts of text data from sources like Wikipedia and BooksCorpus. Its training objectives are masked language modeling (predicting masked words in sentences) and next-sentence prediction (understanding relationships between sentences).
-
Fine-tuning for Specific Tasks: After pre-training, BERT can be fine-tuned on a specific dataset for a particular NLP task, such as sentiment analysis, question answering, text classification, etc. This transfer learning approach allows BERT to achieve state-of-the-art performance across a wide range of NLP tasks with relatively little task-specific data.
2. How BERT works
(1) Tokenization:
-
Step 1.1: Input Processing: BERT first tokenizes the input text. It uses a WordPiece tokenizer, which splits words into subword units (e.g., “playing” becomes “play” + “##ing”). This allows BERT to handle out-of-vocabulary words and capture word morphology.
-
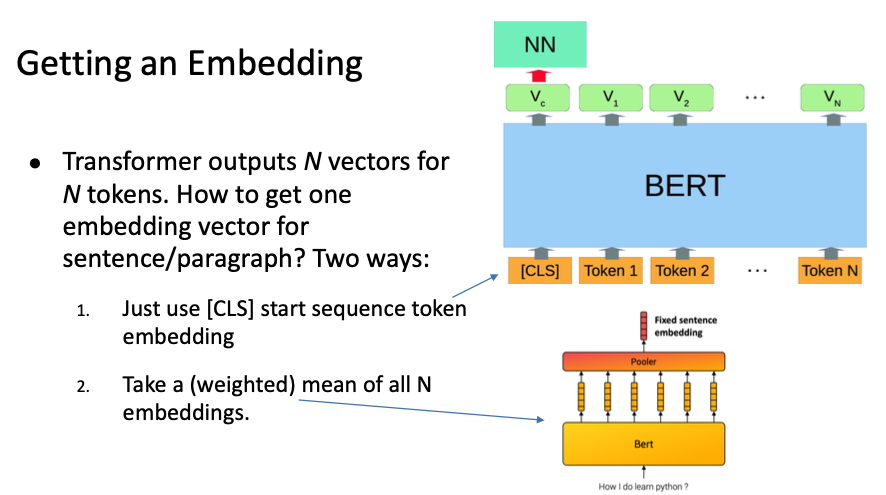
Step 1.2: Adding Special Tokens: BERT expects unique tokens like:
- [CLS]: Placed at the beginning of every input sequence to represent the overall sentence meaning (used for classification tasks).
- [SEP]: Placed at the end of each sentence or to separate two sentences (used for tasks like Question Answering or Next Sentence Prediction).
Source: Lecture 6 - Large Language Models, E2E Deep Learning, Fall 2024, Professor C. Kanan, University of Rochester.
-
- Step 1.3: Token IDs and Input Embeddings
-
The tokenized text is converted into token IDs (numerical representation) that BERT understands. Each token is represented by:
- Token Embeddings: Dense vector representations of words.
- Segment Embeddings: Distinguish between different sentences.
- Position Embeddings: Add positional information about the token’s location in the sequence.
2. Pre-training (Masked Language Model and Next Sentence Prediction):
BERT is initially trained on large datasets using two tasks:
- Step 2.1: Masked Language Modeling MLM):
BERT randomly masks some percentage (typically 15%) of the tokens in the input sequence.
- The task is to predict the masked words based on the context of the other words in the sentence.
- This teaches BERT to understand bidirectional context, unlike traditional left-to-right language models.
- Step 2.2: Next Sentence Prediction (NSP)
- BERT is trained to predict whether two sentences are consecutive or not.
- For each pair of sentences, 50% of the time, the second sentence is the actual following sentence, and 50% of the time, it is a random sentence from the corpus.
- This task helps BERT understand relationships between sentences, which is helpful for tasks like Question Answering and Natural Language Inference.
3. BERT for Other Modalities
- Masked pre-training of transformer encoders is widely used for self-supervised learning for non-language tasks.
- These are called Masked Autoencoders (MAE).
- People have used them for training Vision Transformers (ViT) and CNNs (ConvNextV2).
- They have also been used to learn good features without labels for audio data.
- For vision, they are far from the state-of-the-art, where the best approach is DinoV2.
- However, unlike most self-supervised methods for vision, MAE-based methods do not require augmentations, enabling them to be used with other modalities.
Generative Pre-trained Transformer: GPT
GPT (Generative Pre-trained Transformer) is a series of large language models developed by OpenAI that have made significant advances in Natural Language Processing (NLP) and understanding. GPT models are designed to generate human-like text based on the input they receive, and their architecture has been instrumental in the progress of machine learning, especially in language generation tasks.
1. Key Features
- The original OpenAI transformer is just a decoder stack trained on language modeling (self-supervised).
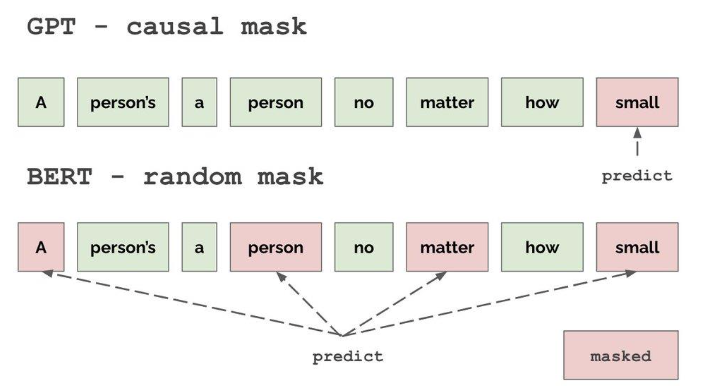
- Process input left to right.
- Train in a self-supervised way to predict the next token given previous tokens.
- This is known as autoregressive training.
- Casual Masking enables parallelization.
- It limits the information in the self-attention head so that each one only has information for previous tokens.
- This enables parallelization during training, so one forward and backward pass for all the text in the context window.
Source: Lecture 6 - Large Language Models, E2E Deep Learning, Fall 2024, Professor C. Kanan, University of Rochester.
2. How GPT Works:
GPT models are built using the Transformer decoder architecture. This model processes the input sequence token by token, predicting the next token based on the observed sequence.
- Tokenization:
- The input text is tokenized into smaller units (either subwords, words, or characters) and converted into numerical representations.
- Input Representation:
- Each token is converted into an embedding, a dense vector that captures its meaning. Position embeddings are also added to account for the token's position in the sequence (since Transformers have no inherent understanding of order).
- Self-Attention Mechanism:
- GPT uses the self-attention mechanism, where each word in the sequence attends to every other word to decide which parts of the input sequence are most important for generating the next word. Unlike BERT, which uses bidirectional attention, GPT only attends to already generated tokens (left-to-right).
- Transformer Decoder Layers:
- The self-attention heads are passed through multiple Transformer decoder layers, which learn complex relationships between words and their contexts. Each layer refines the attention weights, giving the model a more nuanced understanding of how tokens relate to each other.
- Prediction:
- After processing the input through these layers, GPT predicts the following word (token) in the sequence. This prediction process continues, generating word after word until the model outputs a complete sentence or paragraph.
Side Note: BERT vs. GPT
| BERT | GPT |
|---|---|
| Transformer Encoder | Transformer Decoder |
| Bidirectional | Unidirectional (Left to Right) |
| Provides embeddings for downstream supervised tasks on sentences/paragraphs | Generative by default / Can provide embeddings downstream tasks |
| Trained with masking - Masked auto-encoder |
Trained in Autoregressive manner - Predict the next token given previous tokens |
GPT-2, 3 and 4
- Open AI’s GPT-2 is just a giant transformer.
- GPT-2 predicts the next word in a sample of 40GB of internet text.
- GPT-3 has the same architecture as GPT-2. But bigger..
- 175B parameters in GPT-3 compared to 1.5B parameters in GPT-2
- Training GPT-3
- Using the lowest-cost cloud provider in Spring 2020 would cost $4.6M to train!
- They trained 4,789 variants of the model.
- When powered with electricity from fossil fuels, the carbon footprint is 78,000 pounds of CO2 emissions, equivalent to what the average American produces in two years.
- Using the lowest-cost cloud provider in Spring 2020 would cost $4.6M to train!
-
InstructGPT: Reinforcement Learning with Human Feedback (RLHF)
Source: Lecture 6 - Large Language Models, E2E Deep Learning, Fall 2024, Professor C. Kanan, University of Rochester.
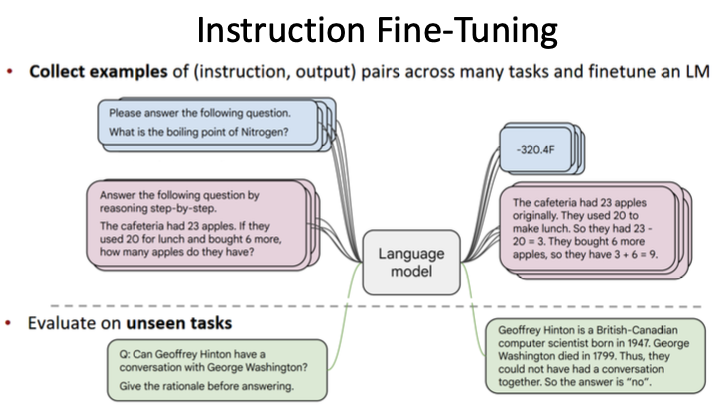
- We need to gather many examples to do this effectively for instruction fine-tuning.
- An alternative approach is reinforcement learning from human feedback, where we create a model to judge the LLM during fine-tuning.
- It involves learning a reward model, typically another LLM, trained on the human feedback data to generate a scalar score (reward).
Leave a comment