
Day85 Deep Learning Lecture Review - Lecture 7
LLMs - Perplexity, Tokenizers, Data Cleaning, and Embedding Layer
General Advice for LLMs
- Start small- Try to use super large models when you need to.
- Try to repurpose existing models over building your own
- Test ideas in papers for yourself
Perplexity
Perplexity is a metric commonly used in Natural Language Processing (NLP) to evaluate language models, especially probabilistic models like those used in text generation tasks (e.g., GPT). It measures how well a model predicts a sequence of words and gives insight into how “uncertain” or “surprised” the model is when making predictions. (Source: https://klu.ai/glossary/perplexity)
-
It measures how well a model can predict the next word based on the preceding context.
-
The lower the score, the better the model’s ability to predict the next word accurately.
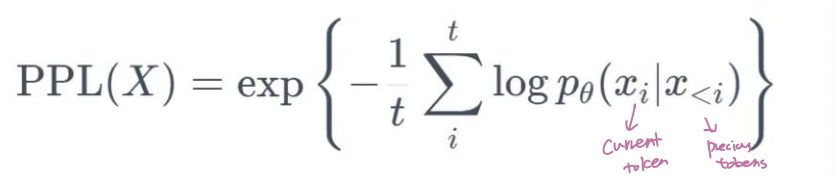
- It means the exponent of the cross-entropy loss (mean of log-likelihood) obtained from the model on the next word prediction task.
-
Interpretation:
- If the model assigns high probabilities to the correct words (or the next word in a sequence), the perplexity will be low, meaning the model is doing well.
- Conversely, if the model assigns low probabilities to the correct words, the perplexity will be high, indicating that the model is “perplexed” or uncertain.
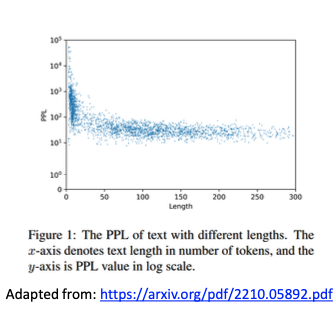
- Limitations:
- Length Sensitivity: Since perplexity is normalized by the number of words in the sequence, it may not always directly correspond to how “good” a model is for long or short sequences. Sometimes, it can be less intuitive than other metrics like accuracy. (For shorter text is larger than longer text)
- Limited Scope: Perplexity focuses solely on the likelihood of predicting the next word, which may not capture other important aspects of language generation, such as fluency, coherence, or factual correctness.
Preprocessing Datasets for LLMs
- Data Deduplication
- A lot of data in webscapes is duplicated. (C4 has a single 61-word English sentence that is repeated 60K times.)
- Training on redundant data can cause overfitting.
- To fix this
- Meta’s D4 Method: Use embeddings on documents and then cluster them with k-means.
- Finding duplicated substrings
- MinHash
- Removal of Toxic Text and Low-Quality Text
- It can be done using classifiers or using heuristics.
- Toxic Text Detection: Use pre-trained toxicity detection models to automatically flag and remove offensive, harmful, or biased content from the training data. Ex) Google’s Perspective API or fine-tuned BERT models.
- Human annotators can review a subset of the data manually.
- Train a classifier using embeddings from a pre-trained LLM, then use the classifier to filter the dataset.
- It can be done using classifiers or using heuristics.
Synthetic “Textbook” Data for Pre-Training LLMs
Synthetic textbook data refers to data that is artificially generated or synthesized to mimic the structure, accuracy, and quality of textbook content. The goal is to provide high-quality, well-organized, and factually correct training data on specific domains or topics, such as science, mathematics, history, or language.
- Using textbooks can enable more compact models that perform equally well as larger models trained on web scrapers.
- Synthetic data (phi-1.5) or using only very high-quality data (phi-1.5-web) enables strong performance with a much smaller model for reasoning, language understanding, coding, and more.
- Approaches:
- Expert Systems and Knowledge Bases
- Leverage Knowledge Graphs: Use knowledge graphs (like Wikidata or ConceptNet) to create synthetic educational content. These knowledge graphs can act as factual backbones, ensuring the data is structured around verified, interconnected facts.
- Textbook Summarization: Summarize large textbook or educational content volumes using extractive or abstractive summarization models. This creates condensed, high-quality text that retains critical concepts.
- Expert Systems and Knowledge Bases
Dataset Mixtures for LLM Pre-Training
Dataset mixtures for pre-training Large Language Models (LLMs) involve combining different datasets to expose the model to diverse language patterns, topics, and domains.
- Common Dataset Mixtures: Weighted Sampling
- Not all datasets in the mixture need to be sampled equally. Assign weights to different datasets based on their importance, size, or quality.
- Balancing Language Registers: Sample uniformity, but then stuck with any portions in the original dataset.
- Domain-Specific Weighting: Sample uniformity, but ensure each batch has samples from each domain.
- Therefore, each batch will have data from all domains.
- However, it can oversample individual domains, which can lead to overfitting.
- Data Filtering
- When using large datasets like Common Crawl, filters are essential to remove low-quality, toxic, or irrelevant data.
- Heuristic-based filtering: Rules for removing specific web domains, overly short text, or non-natural language.
- Classifier-based filtering: Train a classifier to identify and remove low-quality content (e.g., spam, offensive language, or incoherent text).
Tokenizers
-
Token Vocabulary
Token vocabulary in large language models (LLMs) refers to the set of tokens the model can recognize and use as input and output during training and inference processes. Depending on how the model’s tokenizer is configured, a token can be a word, subword, or character.
- We want to be able to generate arbitrary texts.
- Our vocabulary size specifies the output layer size.
- We will have a significant output layer size if we have a vast vocabulary.
- Tokens
- A token can be a word, subword, or character.
- Using characters exclusively would be a small vocabulary, but it would significantly increase inference time.
- Using words exclusively would not allow us to code, and our vocabulary would be gigantic. We would have to remove less common words.
- Subwords would be a compromise.
- Character and subwords ex) Boys = “Boy” + “s”
- Character and subwords ex) Boys = “Boy” + “s”
-
Byte Pair Encoding (BPE)
BPE is an iterative algorithm that starts with characters as individual tokens and merges the most frequent pairs of tokens (subwords) to build a vocabulary. It captures frequent patterns like root words or common affixes.
- It ensures that the most common words are represented as a single token, whereas rare words are broken into subword tokens.
- It creates a base vocabulary containing all ASCII / Unicode characters. Then, iteratively merges tokens to increase the vocabulary size, creating new tokens for the most frequent byte-pair sequences.
-
Special Tokens
-
Special tokens are added to the token vocabulary to handle specific tasks:
- [CLS]: Marks the start of the input (used in BERT for classification tasks).
- [MASK]: Used for masked language modeling (e.g., in BERT).
- [EOS]: Tells the system to stop generating text
-
Embedding Layer
A learnable layer in a neural network that converts discrete input tokens (words, subwords, etc.) into dense vectors (embeddings) of continuous real numbers.
- How do we get tokens into the network? $\rightarrow$ An integer represents each token, and then embedding layers maps tokens to vectors.
- Input: A tokenized sequence (e.g., a list of word or subword IDs).
- Output: A dense vector representation (embedding) for each token.
- In the past, categorical variables were one-hot encoded for input and output. However, this method is still used for the output.
- With an extensive token vocabulary, we would have a vast input embedding **dimensionality**.
- Rather than explicitly using one-hot vectors to encode token embeddings, we use a linear layer that maps integers to unique vectors of floats.
- Words with similar meanings will end up with similarly trained embeddings.
- Words with similar meanings will end up with similarly trained embeddings.
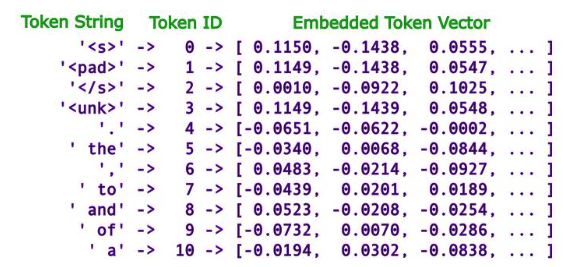
- Step by step:
- An embedding layer maintains an embedding matrix, where each row corresponds to a token's vector representation (embedding) in the vocabulary. During training, the model learns the values in this matrix based on the task it’s solving (e.g., language modeling, text classification).
- Get a token vocabulary of the desired size.
- Tokenize text to map sub-sequences to tokens (integers).
- Integers are mapped to embeddings.
- Embedding Look-up
- When an input sequence (e.g., a sentence) is fed into the model, it is tokenized into a sequence of token IDs. These IDs are then used to look up the corresponding embeddings in the embedding matrix.
- For example, if the input tokens are [23, 45, 101], the model looks up the embeddings for the 23rd, 45th, and 101st tokens in the embedding matrix. The resulting embeddings are then passed to the following neural network layer.
Leave a comment