
Day87 Deep Learning Lecture Review - Lecture 8 (2) & 9
LLMs - Speeding Up LLMs (Grouped Query Attention, KV Caches, MoE, and DPO)

- Speeding Up Transformers
- Flash Attention
- Mixture of Experts (MoE)
- Grouped Query Attention
- Key-Value (KV) Caches
- Routing
Speeding Up Self-Attention
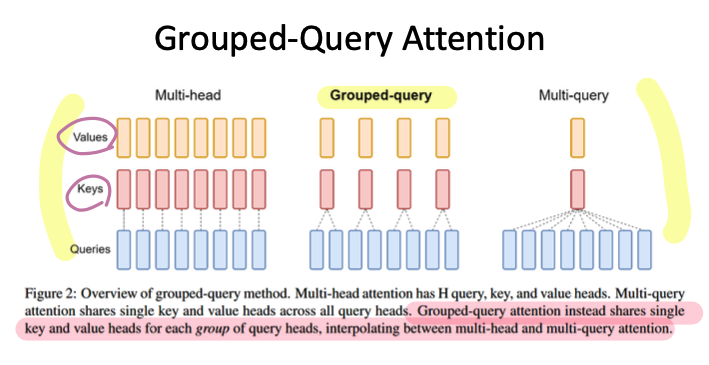
- Grouped-Query Attention
-
The idea behind Grouped-Query Attention is to group multiple queries together and compute attention for these grouped queries instead of performing attention for each query independently.
-
-
Mixture-of-Expert(MoE) Models
<img src="/blog/images/2024-10-09-TIL24_Day87_DL/image-20241009102525802.png"
Source: https://huggingface.co/blog/moe
- MoE (Mixture of Experts) models are a type of neural network architecture that dynamically selects and activates different subsets of “expert” sub-models for processing different parts of an input.
- MoE models can perform highly on diverse tasks by selectively activating specific experts.
- MoE Layer
- In a MoE Layer, the router selects only one expert in the layer for each input to perform computations.
- The Router determines which network to select based on the selection made by a Gating Network.
- Gating Network
- The gating function typically outputs a sparse selection of experts, meaning only a small number of experts are activated for each input, minimizing computation.
- Sparse Activation
- We want to pick just a subset of experts, so most have zero weight and don’t need to be computed.
- Only a few experts are chosen to process each input at a time.

Constitutional AI
- Unlike RLHF, it does not require any human feedback labels for harms.
- Although RLHF doesn’t require that much-labeled data (20K+), it can be unintuitive how to build in safety.
- Constitutional AI ideas:
- Encode the training goals in a simple list of natural language instructions or principles,
- By using chain-of-thought reasoning to make AI decision-making explicit during training and
- Training AI assistants to explain why they are declining to engage in harmful requests.
Scaling Laws for LLMs
- Scaling laws in machine learning and deep learning refer to empirical relationships that describe how a model's performance (e.g., accuracy, loss) improves as various factors, such as the model’s size, the amount of data, or the computational resources, are scaled up. Scaling laws are valuable because they provide insights into how models behave when you increase their capacity, data, or training computing. They help predict the model's performance as it is scaled.
- People have found that scaling laws work, where you can extrapolate performance for larger models from smaller models.
- Variables:
- Our budget
- Size of the model
- Size of the training dataset
- Performance (perplexity, accuracy, etc.)
- Variables:
-
Scaling laws give us insight so you can extrapolate how much of an increase in performance you will get as you change the number of parameters, etc.
- Chinchilla Scaling Laws
- The Chinchilla study from DeepMind challenged the idea that “bigger is always better” by introducing the concept of compute-optimal models. The study found that model performance could be optimized for a given computing budget by adjusting the balance between model size and the amount of data.
- Loss (performance) for a model can be predicted based on the number of training tokens D and the number of parameters N.
- Formula: $L(N,D) = E+ \frac{A}{N^\alpha} + \frac{B}{D^\beta}$
- Train multiple models of various sizes, and then use the scaling law to extrapolate performance for larger sizes.
- This is how OpenAI made GPT-4. They trained many smaller models.
- The Chinchilla study from DeepMind challenged the idea that “bigger is always better” by introducing the concept of compute-optimal models. The study found that model performance could be optimized for a given computing budget by adjusting the balance between model size and the amount of data.
Key-Value (KV) Cache for Transformers
- Using a KV cache greatly reduces the number of matrix multiplications needed and can provide significant speed ups for inference.
LLaMA2
LLaMA (Large Language Model Meta AI) is a family of large language models developed by Meta AI (formerly Facebook AI Research) designed to perform a wide range of natural language processing (NLP) tasks. LLaMA models are open-source and provide an alternative to proprietary models like OpenAI’s GPT-3 or Google’s PaLM.
-
Key innovations include scaling efficiency, where LLaMA balances model architecture and training strategies to deliver strong performance with smaller models.
- LLaMA-13B (13 billion parameters) performs similarly to GPT-3 (175 billion parameters), making it significantly more resource-efficient while still achieving high performance on a variety of NLP tasks.
- LLaMA was trained on a large and diverse corpus of publicly available text data, including books, academic papers, and web text. This broad training dataset enables the model to generalize well across a variety of domains, including scientific literature, technical documents, and general web content.
Phi-1.5
- 1.3B parameter network trained only on synthetic data via the “Textbooks” approach without web scraping
- Can write poems, draft emails, create stories, summarize texts, write Python code, etc.
- Phi-1.5 is a large language model developed by Microsoft as part of its “Textbooks Are All You Need” initiative. It features 1.3 billion parameters and aims to deliver high performance on natural language processing tasks such as common-sense reasoning, coding, and answering questions.
- Despite its relatively smaller size, Phi-1.5 matches or outperforms models that are significantly larger, such as GPT-3 and LLaMA-2, especially in knowledge-based tasks like elementary school mathematics and basic coding.
Retrieval Augmented Generation (RAG)
- RAG (Retrieval-Augmented Generation) is a hybrid model architecture that combines retrieval-based and generation-based approaches in natural language processing (NLP).
- It was introduced by Facebook AI (Meta) and is designed to enhance the capabilities of generative models by integrating a retrieval component that fetches relevant documents or information from an external corpus.
- RAG is form of in-context learning (prompting) work around that enables converting LLMs into information retrieval systems, where they retrieve information from a vector store (vector DB)
- Retriever
- The retriever is responsible for fetching relevant documents or text passages from a large corpus (e.g., Wikipedia, scientific papers, etc.) based on the input query. Typically, a dense passage retrieval (DPR) model is used, where input queries and candidate documents are mapped to embeddings in a shared vector space, allowing for efficient retrieval using similarity search.
- Generator
- After retrieving relevant documents, the generator (often a pre-trained generative model like BART or GPT) takes the query along with the retrieved passages as input and generates a response. The generator model is responsible for synthesizing coherent and contextually accurate output based on both the input query and the retrieved information.
- How RAG works
- Query: A user or system provides an input query or prompt. This query is sent to the retriever, which searches through a large corpus to find the most relevant documents.
- Retrieval: The retriever, typically based on dense vector retrieval methods like DPR or BM25, returns a set of documents or text snippets that are semantically similar or relevant to the query.
- Augmented Generation: The generator (e.g., BART or GPT-2) then combines the retrieved documents with the input query. This augmented input is passed through the generative model, which outputs a response based on both the original query and the retrieved documents.
- Final Output: The generated text is returned to the user as the final response. The combination of retrieval and generation helps the model ground its output in factual information, leading to more accurate and coherent responses.
- Many RAG systems are implemented using LangChain, which also helps connect responses to other apps/systems.
Direct Preference Optimization (DPO)
- Unlike RLHF(Rainforce Learning from Human Feedback) which use the reward model to train our LLM, Direct Preference Optimization (DPO) reformulates RLHF to directly optimize for preferences without training a reward model.
- The idea behind DPO is to leverage user preferences—such as feedback on which outputs or actions are preferred in a given situation— to directly adjust the model’s behavior.
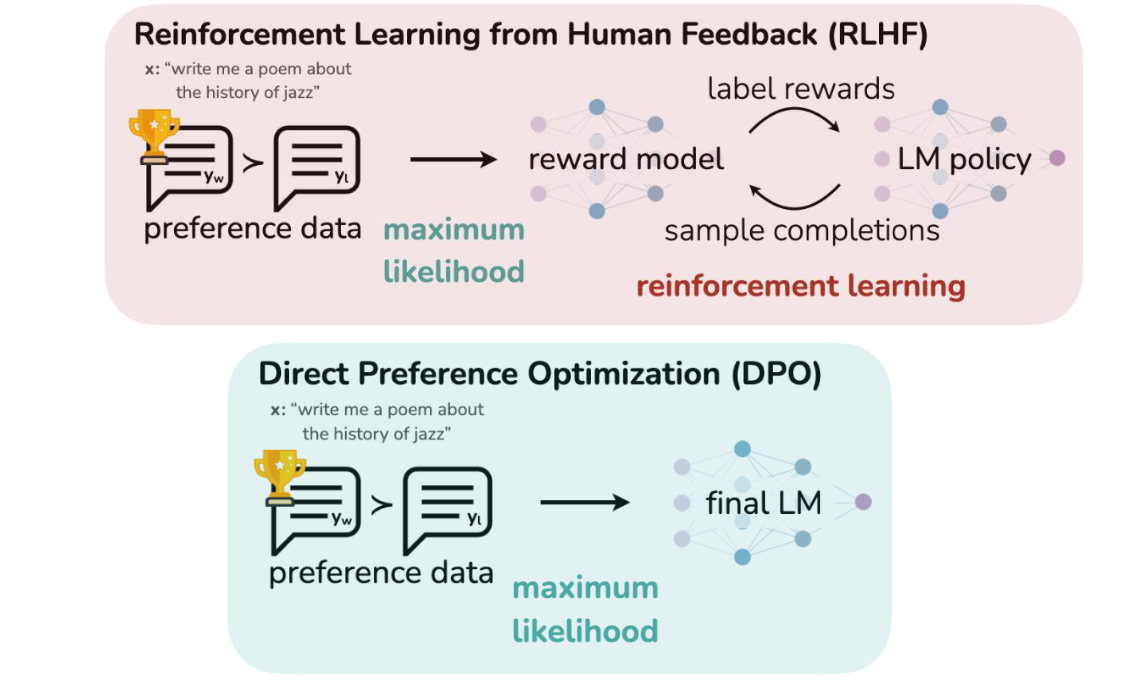
- Instead of traditional supervised learning where the model is optimized based on a loss function (e.g., minimizing the difference between predictions and labels), DPO adjusts the model based on comparisons between two or more outputs. For example, if a user prefers Output A over Output B, the model is updated to increase the probability of generating more outputs like A.
Leave a comment