
Day93 Deep Learning Lecture Review - Fine-Tuning Models (2) & Prompt Engineering
Comparing Pre-trained model embeddings (ResNet+SBERT vs. CLIP) and Prompt Engineering (Short and Direct, Few-Shot Learning, & Expert Prompting)
In my previous post, I employed two pre-trained model configurations—ResNet and SBERT—to create embeddings for Visual Question Answering (VQA) tasks, allowing for comparison with the CLIP model. I will resume my analysis in this post by implementing the CLIP model.
Comparing Pretrained-Model Embedding
4. Embedding Extraction Using CLIP
I utilized the CLIP model in the second setup, incorporating a visual encoder (ViT-B/32) and a textual encoder. Both yielded embeddings of dimension 512. I noted that CLIP’s joint training of visual and textual encoders delivered slightly improved performance compared to the ResNet + SBERT setup, achieving a final test accuracy of 0.3767. Below is the detailed code for extracting embeddings and training with CLIP.
- CLIP (Contrastive Language–Image Pretraining) is designed to align visual and textual representations in the same space. It jointly trains a visual encoder and a textual encoder on a massive dataset of image-text pairs, making it well-suited for tasks like VQA, where both image and text information are critical.
from transformers import CLIPProcessor, CLIPModel
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Extract image embedding
image = Image.open("path_of_the_image")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
image_features = clip_model.get_image_features(**inputs)
# Extract text embedding
text = "This is a sample question."
inputs = processor(text=text, return_tenxors="pt")
with torch.no_grad():
text_features = clip_model.get_text_features(**inputs)
The visual and textual embeddings produced by CLIP were both of dimension 512, resulting in a concatenated embedding of dimension. This more balanced representation provided better alignment between visual and textual information, likely contributing to higher accuracy.
- CLIP? CLIP models (in my experiment,
ViT-B/32) are trained to match images and text representations, which makes them inherently better at understanding the relationship between the two modalities. By using both encoders simultaneously, CLIP generates embeddings that are more likely to be aligned meaningfully, improving performance for multimodal tasks like VQA. - Embedding dimensionality (512): CLIP’s visual and textual embeddings are of dimension 512.
5. Comparison of Setups
Through the experiments, I could analyze the types of questions present in the DAQUAR dataset and compare the performance of two models—CLIP and ResNet + SBERT—on the three primary question types identified: Object, Count, and Color.
-
Question Types and Sample Counts
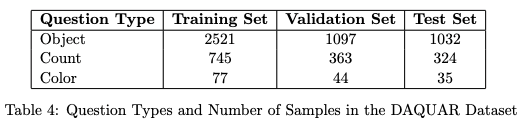
-
Accuracy Score: Both the CLIP and ResNet + SBERT models were evaluated on the test set for each question type. The results show that CLIP slightly outperformed ResNet + SBERT across all question types, as indicated in the table below.

-
Conclusion
- ResNet+SBERT: This setup involves extracting features independently from both modalities (image and text) and concatenating them. Since these models were not trained together, the embeddings might not be perfectly aligned, which could lead to slightly lower performance. Nevertheless, combining a powerful CNN for image embeddings(ResNet-50) and a strong sentence embedding model (SBERT) still provides reasonably good results.
- CLIP: CLIP’s joint training of visual and textual encoders ensures that the image and text embeddings are more naturally aligned. This results in better performance on tasks like VQA, where the relationship between the image and the question is crucial. The fact that both embeddings have the same dimensionality (512) also makes it easier to combine them and train a downstream classifier without additional dimensionality reduction.
In conclusion, CLIP outperforms the ResNEt + SBERT setup because it was designed to create more harmonious and aligned embeddings for text and images, directly benefiting tasks like VQA. Additionally, its balanced dimensionality (512) for image and text embeddings makes the classification task more manageable than the larger combined dimensionality in the ResNet + SBERT setup.
Prompt Design on Fact-Checking with Microsoft Phi-1.5
For this assignment, using the Microsoft Phi-15 model, the task was to explore prompt engineering techniques to understand how different prompt styles influence the quality and accuracy of language model outputs. Here are detailed code snippets and insights.
Background and Objective
The goal was to evaluate how different prompt styles affect the performance of the Microsoft Phi-1.5 model for fact-checking. I observed how different prompting strategies affect the output of this text generation model designed for efficient prompt-based learning. The goal was to classify factual statements as true or false while experimenting with three prompts: Short and Direct, Few-Shot Learning, and Expert Prompting.
Prompt Styles and Experiments
1. Short and Direct Prompts
The Short and Direct prompting style involved minimal instructions to classify statements directly. The prompt format used was:
- “Classify the sentiment as positive or negative: [text]. “
The tested sentences are below.
- “The Great Pyramid of Giza is located in Egypt.”
- “4+4 = 16”
- “Mount Everest is the tallest mountain on Earth.”
- “Bats are blind.”
- “Sharks are mammals.”
- “The sun rises in the west.”
- “Chocolate is made from milk.”
Observations: The Short and Direct prompts generated responses that were often correct but tended to include extra, unrelated information beyond the initial classification. For instance:
- For the statement “The Great Pyramid of Giza is located in Egypt,” the model correctly responded “True” but added irrelevant content about pyramids.
- For “Bats are blind,” it responded “False” and provided some additional, but contextually useful, information about echolocation.
This indicates that the Short and Direct prompting style, while adequate for simple classification tasks, can lead to unexpected elaboration if not carefully constrained.
2. Few-Shot Learning Prompts
The Few-Shot learning involved providing the model with a few labeled examples before making a prediction. The prompt format was as follows:
- “Statement: ‘The moon is made of cheese.’\nAnswer: False\nStatement: ‘The Eiffel Tower is located in Paris.’\nAnswer: True\n[text]\nAnswer:”
Observations: The Few-Shot Learning approach provided better consistency and accuracy than Short and Direct prompts. For example:
- The Statement “4+4 = 16” was correctly classified as “False,” showing improved understanding after being given examples.
- After the answer, the model generated additional elaboration, indicating a tendency to add context even with structured guidance.
The labeled examples helped guide the model to more accurate predictions, particularly for misleading or tricky statements.
3. Expert Prompting
from transformers import pipeline
# Load Microsoft Phi-1.5 model for text generation
generator = pipeline("text-generation", model="microsoft/phi-1_5")
# Statements to fact-check
statements = [
"The Great Pyramid of Giza is located in Egypt.",
"4 + 4 = 16.",
"Mount Everest is the tallest mountain on Earth.",
"Bats are blind.",
"Sharks are mammals.",
"The sun rises in the west.",
"Chocolate is made from milk.",
]
# Expert Prompting style
expert_prompt = "You are a world-renowned fact-checker. Please carefully verify the following statement and explain whether it is true or false in detail: {}"
def expert_fact_check(statement):
# Generate the expert prompt
prompt = expert_prompt.format(statement)
# Use the Phi model to generate a response based on the expert prompt
result = generator(prompt, max_new_tokens=100, num_return_sequences=1)
return result[0]['generated_text']
# Testing all statements with Expert Prompting
for statement in statements:
print(f"\nStatement: {statement}\n")
print("Using Expert Prompting:")
output = expert_fact_check(statement)
print('-' * 20)
print(output)
print('-' * 40)
In the Expert Prompting technique, the model was asked to assume the role of a knowledgeable entity. The prompt was:
- “You are a world-renowned fact-checker. Please carefully verify the following statement and explain whether it is true or false in detail: [text].”
Results and Observations:
- “Bats are blind.”
- The model correctly responded with “False” and provided a detailed explanation of bats’ uses of echolocation, stating that although bats do not see like humans, they are not blind. This showed the model's ability to provide more comprehensive information.
- “Sharks are mammals.”
- The answer provided was “False,” clarifying that sharks are classified as fish rather than mammals, and presented the idea of a logical fallacy.
- “The sun rises in the west.”
- The model accurately responded with “False,” explaining that the sun rises in the east due to Earth’s rotation.
- “Chocolate is made from milk.”
- Here, the model incorrectly classified the statement as “True” and provided an incomplete explanation, indicating a limit to its knowledge or difficulty differentiating between true chocolate ingredients.
- Here, the model incorrectly classified the statement as “True” and provided an incomplete explanation, indicating a limit to its knowledge or difficulty differentiating between true chocolate ingredients.
Comparison and Insights
- Accuracy and Coherence
- Expert Prompting generated more detailed and coherent responses. The explanations were generally more prosperous and more informative than those produced by the other prompt styles.
- However, Expert Prompting did not continuously improve accuracy. For instance, in the case of “Chocolate is made from milk,” the model’s response was incorrect but more detailed. This shows that adding an “expert personality” can lead to elaborative reasoning, but it may not always align with the correct factual outcome.
- Trade-Off between Depth and Accuracy
- While the Expert Prompting approaches often generated more comprehensive responses, this did not guarantee an improvement in factual correctness. The model still struggled with some basic factual inconsistencies, indicating that the added complexity of the prompt might lead to richer but not necessarily more accurate results.
- While the Expert Prompting approaches often generated more comprehensive responses, this did not guarantee an improvement in factual correctness. The model still struggled with some basic factual inconsistencies, indicating that the added complexity of the prompt might lead to richer but not necessarily more accurate results.
Conclusions
-
Prompt Style Matters: The structure of the prompt significantly impacts the models’ behavior. Short and Direct prompts produce straightforward but sometimes incomplete or contextually irrelevant answers. Few-Shot Learning improves the model’s contextual understanding by providing examples and better accuracy for specific tasks.
-
Expert Prompting Insight: Expert prompting gave the model an “expert personality,” which resulted in more elaborate responses, but factual correctness did not always improve. This suggests that while Expert Prompting can enhance the coherence and depth of responses, it requires careful crafting to ensure accuracy.
-
Practical Application: In a real-world application, selecting the appropriate prompt style depends on the use case.
For tasks where detailed explanations are as important as accuracy, Expert Prompting might be beneficial.
However, a structured Few-Shot Learning approach might yield better results without unnecessary elaboration for direct fact-checking tasks.
Leave a comment