
Day94 Deep Learning Lecture Review - Lecture 13
Llama 3: Framework, Workflow (RMSNorm, Grouped Query Attention, RoPE, SwiGLU Attention), Pre-training & Post-training

Llama 3
Llama 3 is Meta’s latest generation of open-access large language models (LLMs). It builds upon the architecture of Llama 2 but incorporates significant upgrades. Available in versions with 8 billion to 70 billion parameters, Llama 3 also includes a massive 405 billion parameter variant, which puts it on par with some of the most capable language models available.
Deep-Dive into Llama 3
Framework
Image Source: https://www.youtube.com/watch?v=bZQun8Y4L2A and adapted for Llama3
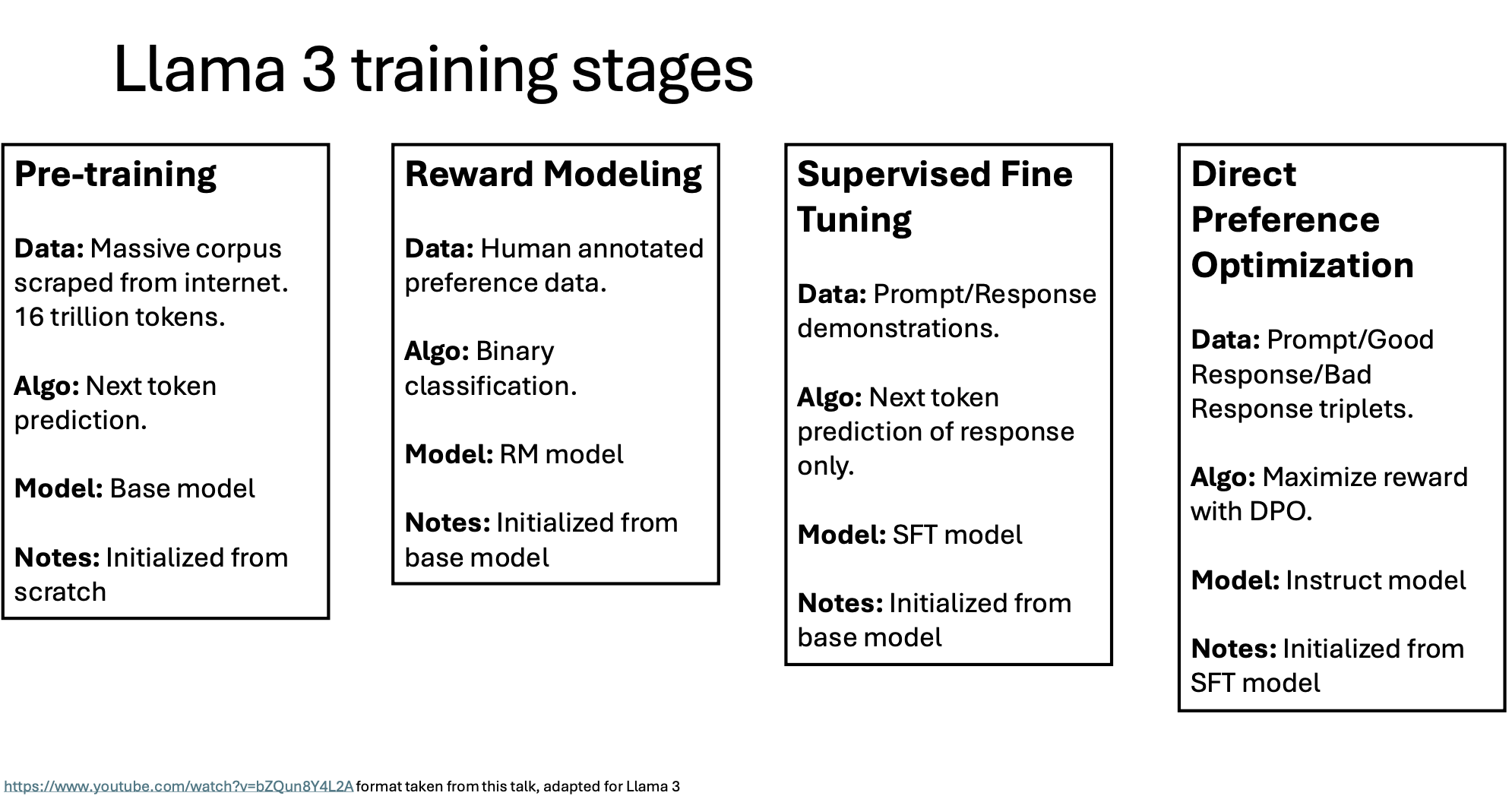
- Pre-training: This initial stage involves training on a massive dataset of 16 trillion tokens scraped from the internet. The model learns language structure and world knowledge through next-token prediction, creating a base language model from scratch.
- Reward Modeling: This stage trains the model to differentiate between more or less favorable responses using human-annotated preference data. It uses binary classification to build a reward model that assesses response quality.
- Supervised Fine Tuning (SFT): In this method, the model is refined on prompt-response pairs, predicting the next token only within the response context. This helps align the model’s outputs with expected conversational patterns.
- Direct Preference Optimization (DPO): In the final stage, the model is further optimized by training on triplets of prompts with good and bad responses, maximizing rewards using the DPO method. This step aligns the model with human preferences, enhancing its assistant-like responses.
Workflow
Image source: UnfoldAI - Meta Llama 3
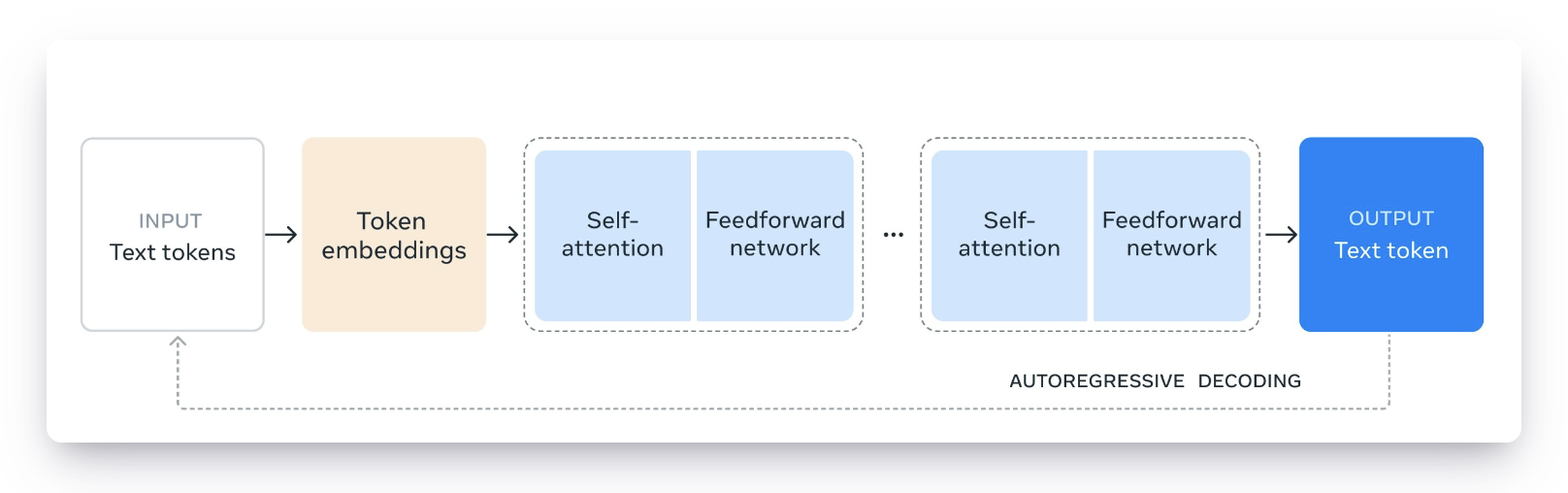
- Decoder-only Transformer
- RMSNorm
- Grouped Query Attention (GQA)
- Rotary Positional Encoding (RoPE)
- SwiGLU activation
RMSNorm
- It is a simpler and faster alternative to layer norm.
- In short, LayerNorm provides both re-centering and re-scaling, while RMSNorm relies solely on re-scaling, often “all you need” for stability and efficiency.
- LayerNorm: Layer Normalization (LayerNorm) stabilizes the training of deep networks by normalizing inputs across features. It provides both re-centering (adjusting the mean) and re-scaling (adjusting the variance), making the model invariant to shifts and scales in the input.
- RMSNorm: Root Mean Square Normalization (RMSNorm) simplifies LayerNorm by focusing only on rescaling. It doesn’t center the mean of inputs but normalizes them by scaling only, leveraging the observation that rescaling alone often suffices for stable model training.
Grouped Query Attention (GQA)
- It is an optimization for multi-head attention in Transformer models.
- GQA optimizes multi-head attention by sharing some K and V across heads, significantly reducing memory requirements for caching and improving inference speed.
- Traditional Multi-Head Attention: Typically, each head in multi-head attention has its own unique sets of queries (Q), keys (K), and values (V). This approach requires storing individual K and V pairs for each head, which can significantly increase memory usage.
- For example
- In traditional Multi-Head Attention, each head has 64 dimensions. Since we have 8 heads, we would need to store 8 sets of 64-dimensional K and V matrices, which can become memory-intensive.
- With GQA, let’s assume we group these 8 heads into 4 groups, where each group shares the same K and V but has a separate Q for each head. Instead of 8 sets of K and V, we only need 4, reducing the memory requirement by half.
Rotary Positional Encodings (RoPE)
- A technique used in Transformers to include the position of tokens in a sequence while keeping important features for long-context attention.
- RoPE provides position information, which helps attention scores decrease with distance. This allows the model to maintain context and focus more on recent tokens, which helps it work</u> with long sequences.
- Workflow:
- Define Attention Mechanism: In transformers, each token in a sequence attends to other tokens using queries (Q), keys (K), and values (V). The attention score, determining how much one token should focus on another, is calculated based on the inner product between Q and K.
- Add Positional Information with RoPE: RoPE encodes the position of each token in Q and K vectors by applying a rotational transformation. This step injects position data into the model, allowing it to recognize the order of tokens without fixed position embeddings.
- Decay Attention over Distance: As the distance between tokens increases, the inner product (attention score) between their Q and K vectors naturally decays. This decay means the model pays less attention to tokens that are far apart, helping it focus on nearby relevant contexts.
- Maintain Local Focus in Long Sequences: If the model reads “The sky is blue” and encounters a similar phrase much later, RoPE ensures it won’t focus too heavily on that distant phrase, preserving the sequence’s flow without excessive long-range dependency.
SwiGLU (Swish-Gated Linear Unit)
-
An activation function is used in neural networks, particularly transformers, to improve model performance and efficiency. It combines two elements.
- Swish Activation: SwiGLU uses the Swish function, defined as $x \times \text{Sigmoid}(x)$. This function provides smooth, non-linear transformations that help the model learn complex patterns.
-
Gating Mechanism: SwiGLU applies a gating layer, which multiplies the Swish-activated values with another linear input transformation. This gating introduces an additional non-linearity, allowing the model to control the amount of input passed through.
Pre-Training Llama 3
- Data Collection: Llama 3 is trained on a massive, diverse corpus of text gathered from the Internet, which includes a wide range of languages, topics, and styles. Meta used around 16 trillion tokens for Llama 3, significantly more than many previous models, which helps the model generalize better across different domains.
- Tokenization: The data is tokenized into smaller units (tokens) that the model can process. Llama 3 uses an 8K token context window, allowing it to process and remember longer text sequences effectively during training, later extending this window to 128K tokens for longer-context capabilities.
- A tokenizer determines vocabulary.
- Next-Token Prediction Objective: The core training objective for Llama 3 is next-token prediction, where the model learns to predict the next word in a sentence based on the previous words. This setup enables it to generate coherent and contextually relevant text across various tasks.
- Scaling and Optimizations: Llama 3 is trained at scale, with over 405 billion parameters for the most significant model variant. Meta uses optimized hardware setups, such as distributed training across data centers, to handle the model’s computational demands.
- Pre-training and Fine-tuning for Specialized Tasks: Once the base model is pre-trained, Llama 3 undergoes further training (post-training or fine-tuning) for specific tasks, aligning it more closely with practical applications like code generation, question-answering, and reasoning.
Web Data Curation
For Llama 3, web data curation is a critical step in gathering high-quality, diverse, and relevant text data for training. This process involves several key actions:
- Source Selection: Meta selected a wide range of publicly available web content, including multiple languages and content types, to provide a well-rounded training dataset that can enhance the model’s language abilities across domains.
- Filtering and Cleaning: Not all web data is suitable for training. Llama 3’s data curation includes filtering out low-quality or harmful content, such as spam or biased language, to improve the model’s reliability and safety. This process involves both automated filters and manual reviews.
- Handling Personally Identifiable Information (PII) ensures user privacy and model safety. Handling Personally Identifiable Information (PII) ensures user privacy and model safety when curating data for Llama 3.
- Filtered at the web domain level
- Filter out domains with high amounts of PII.
- Filter out domains ranked as having harmful content.
- Filter out domains known to have adult content.
- The cleaning process will be included below.
- Custom HTML parser
- Optimizes precision of removing boilerplate and recalling content
- Math and code web pages are handled with special care.
- Markdown markers removed
- Handling Personally Identifiable Information (PII) ensures user privacy and model safety. Handling Personally Identifiable Information (PII) ensures user privacy and model safety when curating data for Llama 3.
- Balancing Data: To prevent the model from over-relying on specific content sources, Meta curated data with a balanced representation across topics, genres, and languages. This balancing helps Llama 3 generalize better across diverse applications and avoid biases.
- De-duplication: want to avoid duplication of content so as not to skew distribution
- URL-level de-dup: keep the most recent version of the web page
- Document-level de-dup: global MinHash across the entire dataset
- Line-level de-dup: remove lines that appear >6 times in buckets of 30M docs
- De-duplication: want to avoid duplication of content so as not to skew distribution
- Tokenization and Preparation: After selection, the data is tokenized, meaning it’s broken down into manageable units (tokens) for the model. This tokenized data feeds into the pre-training process, where the model learns patterns, relationships, and language structure from the vast corpus.
Heuristic Filtering
Heuristic filtering in training models like Llama 3 involves predefined rules or “heuristics” to screen and remove low-quality or undesirable data from the training corpus.
- If you want to remove low-quality docs, outliers, and documents that are excessively repetitive.
- Duplicated n-gram coverage ratio to remove repetitive docs such as logging/error messages
- “Dirty word” counting to filter adult websites not covered in the block list
- KL divergence of token distribution to remove outliers
Llama 3’s Pre-Training
-
Initial Pre-Training:
- This is the foundational training phase, during which the model learns basic language patterns, syntax, semantics, and general world knowledge.
- Using a vast dataset, the model is trained on a next-token prediction task — predicting the next word in a sequence based on the previous words.
-
Long Context Pre-Training:
-
After initial pre-training, the model undergoes additional training to handle longer sequences. The context window is extended (up to 128,000 tokens in Llama 3) to allow the model to manage long-range dependencies better.
-
This step teaches the model to retain and make sense of information in long texts, which is crucial for document summarization, multi-turn conversations, and document analysis.
-
-
Annealing:
-
Annealing involves gradually reducing the learning rate during training to stabilize the model’s performance and prevent overfitting.
-
Polyak Averaging (or Exponential Moving Average (EMA) of weights) is used in training neural networks, including Llama 3, to improve stability and performance.
-
Image Source: Papers With Code: Polyak Averaging
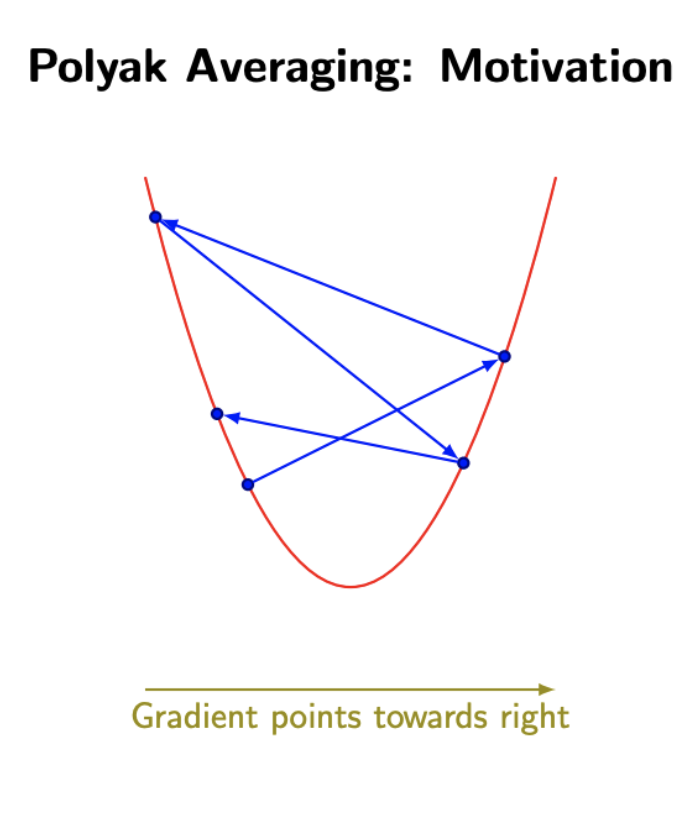
-
Polyak Averaging is a method used in optimization that averages the recent parameters encountered during the process to set the final parameters. Specifically, if in $t$ iterations we have parameters $\theta_1, \theta_2, \dots, \theta_t$ then Polyak Averaging suggests setting: $\theta_t = \frac{1}{t} \sum_i \theta_i$
- Weight Averaging: During training, instead of using just the most recent set of model weights, Polyak Averaging maintains an average of past weight values over time
- Stabilizing Training: Averaging weights over time helps smooth out abrupt changes, making the final model more stable.
- Improved Generalization: Polyak Averaging can lead to better generalization, as the averaged weights represent a broader “consensus” over the training process, rather than specific weight configurations that may overfit to recent data batches.
- Enhanced Performance at End of Training
-
This gradual decrease in the learning rate allows the model to make finer adjustments as it converges, improving its generalization ability and reducing the risk of getting stuck in local minima.
Post-Training
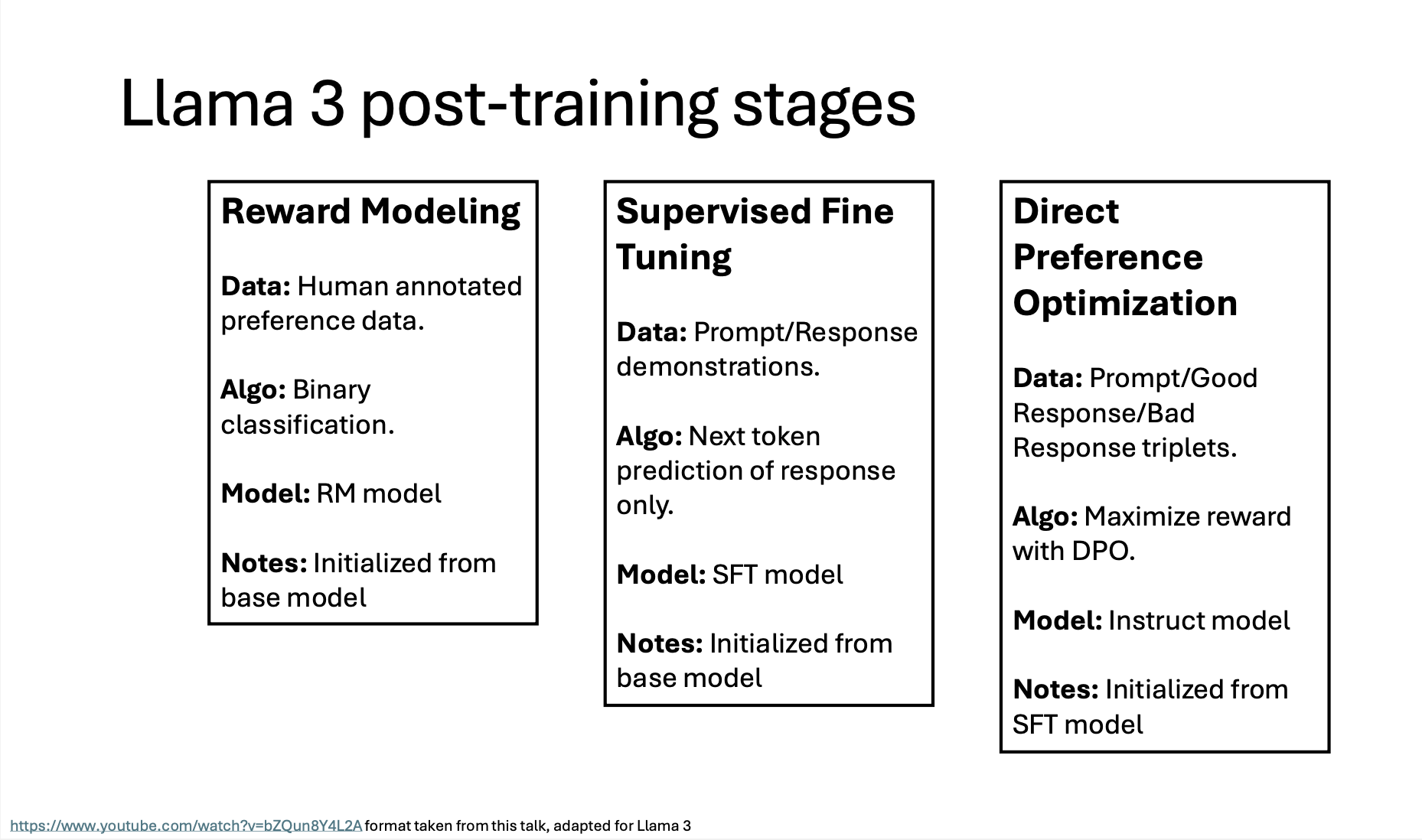
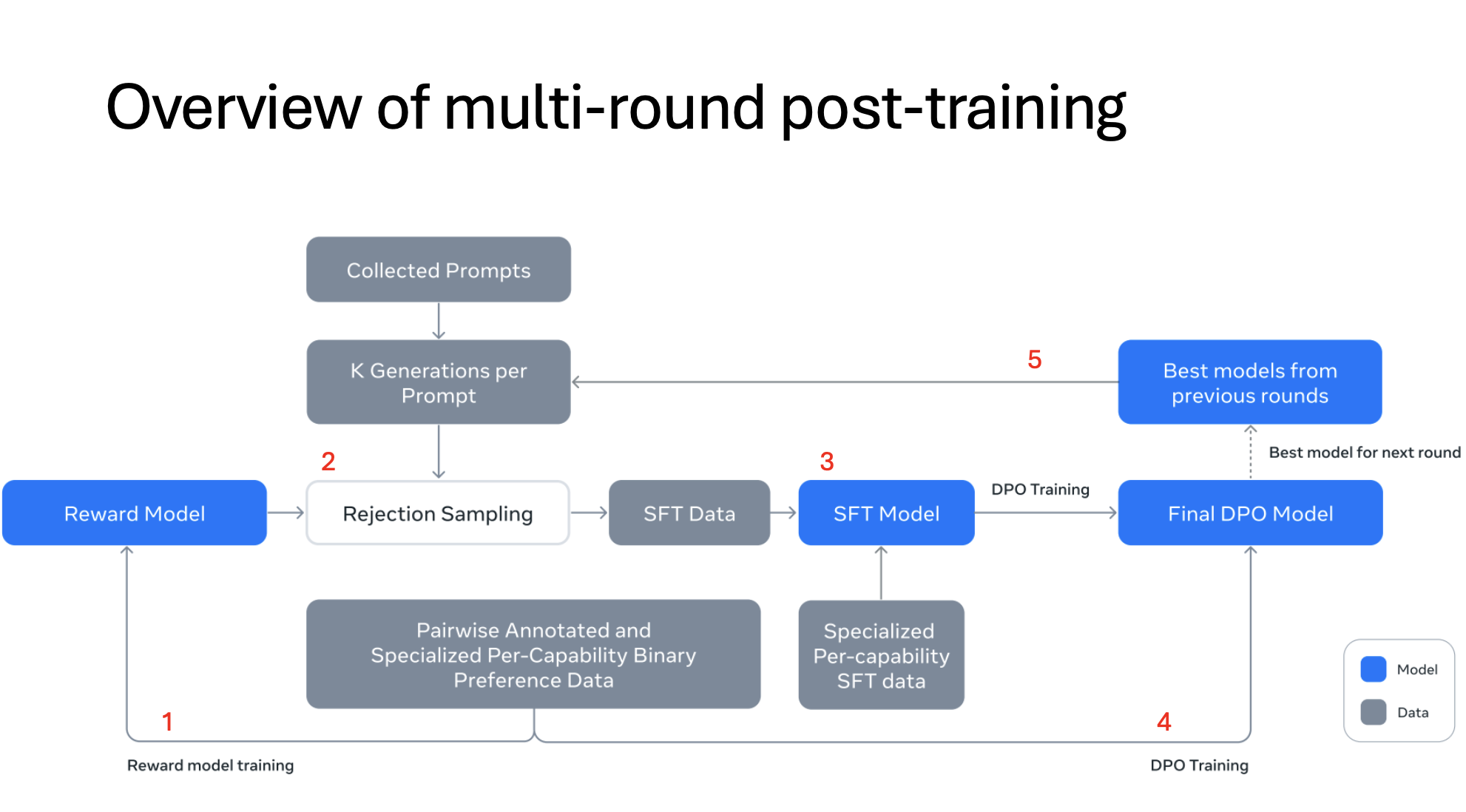
The image outlines the post-training stages for Llama 3, which refine the model for better performance and alignment with human preferences. Below is a brief explanation of each stage.
- Reward Model Training
- The process starts by training a Reward Model using human-annotated preference data. This model scores responses based on how well they align with human preferences.
- The results: Rejected, Chosen, and Edited
- Rejection Sampling
- Prompts are collected, and the model generates multiple responses for each (K generations per prompt).
- Rejection sampling uses the reward model to filter out low-quality responses, leaving only those that meet a certain quality threshold. This filtered data becomes the input for the next stage.
- Supervised Fine-Tuning (SFT)
- The SFT Model is trained on the selected, high-quality responses from rejection sampling. This model learns to generate better responses based on prompt/response pairs.
- Additional specialized data (per-capability preferences data) may be used to fine-tune specific capabilities, enhancing the model’s ability in various response types.
- Synthetic data for specific capabilities.
- Direct Preference Optimization (DPO) Training
- The DPO Model is created by further refining the SFT Model. Using Direct Preference Optimization, the model learns to prefer "good" responses over "bad" ones based on preference triplets (prompt, good response, lousy response).
- This optimization helps align the model’s outputs with human expectations more effectively.
- Iterative Best Model Selection
- The best-performing models from each training round are saved and used as a base for the next round of training, allowing the model to improve iteratively.
- This process may repeat multiple times, leveraging the best model from previous rounds to produce increasingly refined and aligned outputs.
Synthetic Data Generation Strategies for LLM Training
- Data Augmentation: Techniques such as synonym replacement, back-translation, and paraphrasing can create variations of existing text, enhancing training data diversity without changing the meaning. For LLMs, paraphrasing at a sentence or paragraph level can be especially useful for expanding conversational contexts.
- Back-translation
- Generate: Prompt Llama 3 to generate data for target capability (e.g., add comments and docstrings for the code snippet or ask the model to explain a piece of code).
- Backtranslate: Prompt model to generate code only from its documentation or ask the model to generate code only from its explanation.
- Filter: Using the original code as a reference, prompt model to determine the quality of the output (i.e., ask the model how faithful the backtranslated code is to the original). Use the generated examples that have the highest self-verification scores in SFT.
- Back-translation
-
Leave a comment