
Day96 Deep Learning Lecture Review - Lecture 15 (1)
Model Comparison and Bias Mitigation; McNemar’s Test, Dataset Bias, and Bias Detection

Model Comparison
The lecture highlights that merely evaluating models based on overall accuracy or error metrics tends to overlook important details, especially for deep learning systems used in various contexts.
- How Do We Tell if a Model is Better?
- Machine learning papers often report the result of a single run, but this approach could be more reliable. Deep learning models exhibit variance due to random initializations.
- Different random seeds can lead to other models, affecting their overall performance.
- Point Estimates Aren’t Sufficient.
- Metrics like mean accuracy provide only a limited view.
- Carefully well-designed experiments are needed.
- Must identify relevant sub-groups.
- Analysis methods for comparing models:
- Confidence Intervals
- Hypothesis testing
Confidence Interval
-
Confidence Intervals are recommended to add bounds to these estimates. If confidence intervals between models do not overlap, there is a statistically significant difference.
-
A smaller confidence value indicates a more precise estimate.

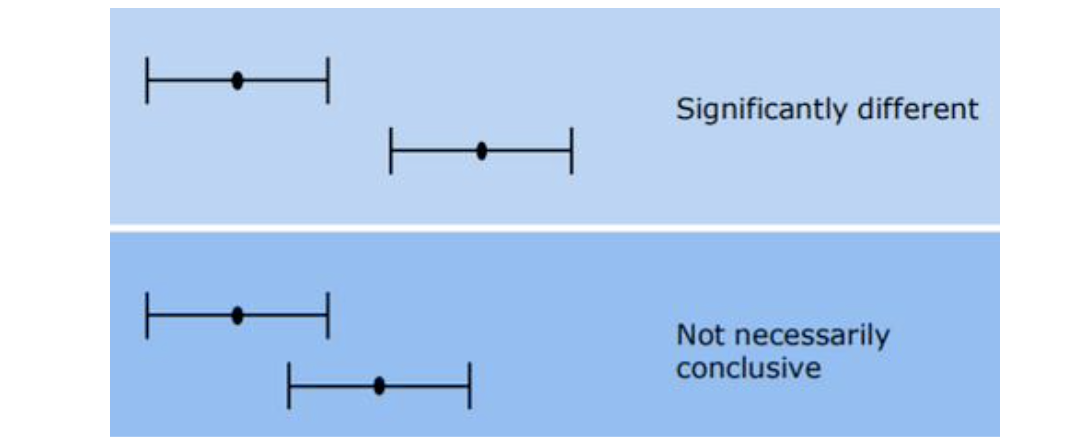
- If the confidence intervals do not overlap, they are significantly different, and the one with the best accuracy could be chosen.
-
If they overlap, the results are not necessarily conclusive.
-
What if the distribution is non-Gaussian?
-
We could use non-parametric methods instead, e.g., a bootstrap estimator.
-
Confidence intervals do not take paired data into account, but often, we evaluate two models on the same data, so a paired test makes sense.
-
McNemar’s Test
- Often, we want to compare two models using paired data, i.e., the same dataset.
- We want to compare the behavior of two models in each example.
- Image 1: Model 1 vs Model 2
- Image 2: Model 1 vs Model 2 …
- We want to compare the behavior of two models in each example.
- McNemar’s Test is a statistical test for paired nominal data.
- It is most commonly used for binary classifiers, but it can also be used for multi-class.
- McNemar’s Test tells you that the one with the lower error is probably better if two classifiers are unequal.
- We need to construct a 2x2 contingency table for each model.
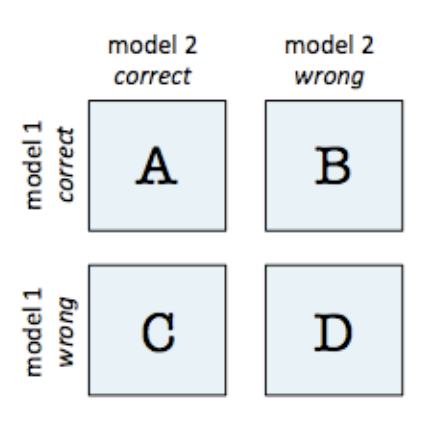
- Count how many times the models were:
- Both models were correct.
- Model 1 was correct, but Model 2 was incorrect.
- Model 2 was correct, but Model 1 was incorrect.
- Both models were wrong.
- Set significance level of alpha, typically set to 0.05 (95%)
-
$n = B+C$ , and $p = 2 \sum^n_{i=b} \binom n i 0.5^i (1-0.5)^{n-i} $
- Example : Two Scenarios
- For Scenario A:
- We get a p-value of 0.006, which is less than an alpha of 0.05, so we can reject the null hypothesis that both perform equally well.
- So in Scenario A, model 2 is better.
- For Scenario B:
- We get a p-value of 0.155, which is greater than an alpha of 0.005, so we cannot reject are null hypothesis and assume there is no significant difference.
- So in Scenario B, models perform equally well.
- For Scenario A:
- Various statistical tests are available. Relying solely on whether the population statistic (mean accuracy) is greater can mislead model selection.
- Many AI researchers rely solely on point estimates to compare models, and neglecting statistical analysis and thoughtful design constitutes poor scientific practice.
Bias in Machine Learning
In the real world, the datasets often matter much more than the AI algorithms, as they serve as the foundation for meaningful insights and informed decisions. The lecture highlights that dataset bias and algorithmic bias are significant concerns in machine learning. The data used to train AI systems can include various forms of bias, leading models to make decisions that are not universally applicable or fair.
Dataset Bias
- Deep learning struggles to learn the correct abstractions and behavior when dataset bias exists.
- Dataset bias is tricky to track down.
- However, the datasets are almost always biased.
- Types of Bias in Datasets
- Photographer Bias: Images may reflect subjective perspectives, leading to bias in representing categories.
- Sample Bias: Non-representative sampling can lead to overrepresented groups or features.
- Sequence Bias: Training data is often not i.i.d (independent and identically distributed), meaning patterns in sequences could be mistakenly inferred.
- Racial Bias: When datasets over- or under-represent specific racial groups, the AI model will likely inherit these biases.
- Covariates and Confounders
- Covariates: Variables that co-vary with the target variable.
- Removing an input variable like race may not eliminate bias if other correlated variables remain, leading the model to learn biased patterns.
- For example, suppose you remove “race” as an input variable to make your system less biased but still include zip code. Your model will still learn race since race is correlated with zip code in the USA.
- In general, aim to identify all subpopulations and assess their performance. To compare the population statistics, you can use hypothesis testing.
- When optimizing a model, it will use all of the information you provide the model.
- Confounders: Variables representing misleading associations
- When you train a model to identify bird species, it may struggle with photos of birds that aren’t in flight, especially if certain species are predominantly captured while flying.
- If wolves always appear with snow, the model may learn snow rather than wolves.

- No matter the dataset’s size, deep learning systems can still learn biases that fail to generalize.
- These systems can be “correct for incorrect reasons.”
- Even when trained on a dataset that reflects real-world conditions, the systems often struggle with rare but critical instances.
- Emulating real-world biases should not be the aim!
- More than simple training on extensive datasets is required!
- Traditional machine learning systems, exceptionally standard deep neural network approaches, tend to learn the biases present in the dataset.


- It is essential to thoughtfully design studies to determine if our systems function correctly for unintended reasons.
- We need to develop algorithms that effectively resist incorporating bias from datasets.
- These algorithms should operate under the assumption that they lack explicit access to all potential sources of bias, as many biases are often concealed.
- The key takeaway is the importance of conducting careful studies to ensure that AI systems are “working correctly for the right reasons”—that is, they are not relying on unintended, biased patterns that correlate with the correct output.
Two Stories of Bias Detection
The lecture introduces two real-world examples that illustrate how bias can impact AI systems:
- Detecting Bias in Medical AI Systems: A story about an AI system that detects pancreatic cancer in CT scans.
- Bias in Language-Guided Scene Understanding: Using visual and textual information to understand images in biased ways, often relying on shortcuts rather than understanding. (VQA System)
1. Medical AI Bias Example
Let’s discuss an example of the AI system for pancreatic cancer detection.
-
Initial Success and Caution:
- The AI system developed outperformed sub-specialist radiologists, achieving an impressive AUC (Area Under the Curve) of 0.95.
- However, the system seemed to work “too well,” especially given the relatively small dataset of 162 CT scans (82 of which were cancerous). This raised red flags for potential biases.
- Sanity Tests:
- The team performed several sanity checks to ensure the model wasn’t relying on unintended cues:
- Blacked-Out Pancreas Experiment: They used segmentations to mask out the pancreas entirely from CT scans and then retrained the model. Surprisingly, the model performed even better—indicating that the original model wasn’t genuinely learning from the pancreas but was relying on other features correlated with cancerous scans.
- Noise and Background Information: The system was trained using background or noise information to see if it could distinguish between normal and cancerous cases. Again, the model’s performance suggested that it might be picking up on irrelevant but correlated features.
- The team performed several sanity checks to ensure the model wasn’t relying on unintended cues:
- Results of Sanity Tests:
- The results confirmed that the model’s AUC was nearly the same whether it was trained with or without pancreas data. This suggests it relied on spurious correlations, such as the settings used during the scans, which differed between cancer and non-cancer patients.
- This example illustrates that, without careful validation, models might appear adequate while relying on flawed or biased data.
2. Visual Question Answering (VQA) and Bias
We have also discussed Visual Question Answering (VQA) and its associated biases. VQA is a task that combines computer vision and natural language processing to answer questions based on images.
- Introduction to VQA and Bias
- What is VQA?
- VQA requires a model to understand both the visual content of an image and the context of a question
- For example:
- “How many people are wearing ties?” involves both counting and attribute detection.
- “What event is happening?” involves scene classification.
- The Goal of VQA
- A desire to create systems that can perform a wide range of tasks, similar to a Visual Turing Test—a benchmark for creating models that exhibit true visual competence.
- A desire to create systems that can perform a wide range of tasks, similar to a Visual Turing Test—a benchmark for creating models that exhibit true visual competence.
- What is VQA?
- Bias in VQA Systems
- Rapid Progress and Shortcomings
- Although the VQA field progressed rapidly (as illustrated by increasing benchmark results), biases persisted in the datasets.
- It was discovered that VQA models could often achieve high accuracy by relying on language priors—common patterns in questions and answers—instead of understanding the image content.
- “Right for the Wrong Reasons”
- An important observation was that sometimes models performed well not because they had a deep understanding of the visual content but because they learned shortcut strategies based on biased dataset distributions.
- An important observation was that sometimes models performed well not because they had a deep understanding of the visual content but because they learned shortcut strategies based on biased dataset distributions.
- Rapid Progress and Shortcomings
-
Bias in VQA Datasets
- Language Priors and Dataset Bias
- For example, a VQA model might learn that if the question begins with “Is there…”, the answer is often “yes.” This is a shortcut and not a genuine analysis of the image.
- Such biases were widespread, leading researchers to question the robustness of VQA models.
- Language Priors and Dataset Bias
- Introduction of VQA-CP
- To address this, a new dataset called VQA-CP (Visual Question Answering - Changing Priors) was introduced. This dataset was designed to have different answer distributions in the training and test sets, encouraging models to rely less on language priors and more on image understanding.
- The dataset introduced a significant domain shift between the training and testing sets to assess the model’s robustness to dataset bias.
- Mixed Success in Bias Mitigation
- Although some methods showed improvements on the VQA-CP dataset, follow-up research by the lecturer’s team (shown in ACL-2020 and NeurIPS-2020) demonstrated that many of these methods did not generalize well and often performed similarly to very simple approaches.
- This highlighted the persistent challenge of bias in multimodal learning and the difficulty of developing models that genuinely understand both visual and textual content.
Leave a comment