Wonha (Leah) Shin

Machine Learning & MLOps Engineer
I design, build, and scale intelligent systems — from streaming NLP pipelines to real-time LLM applications. Driven by curiosity, I combine data engineering with AI research to turn ideas into production-ready systems.
View My LinkedIn Profile
💬 Cross-Linguistic NLP Analysis of E-Cigarette Perceptions on Social Media
Python | Hugging Face | BERTweet | Twitter Twin BERT | Sentence-BERT | UMAP | K-Means | BERTopic | Multilingual NLP | Public Health AI
🌍 Overview
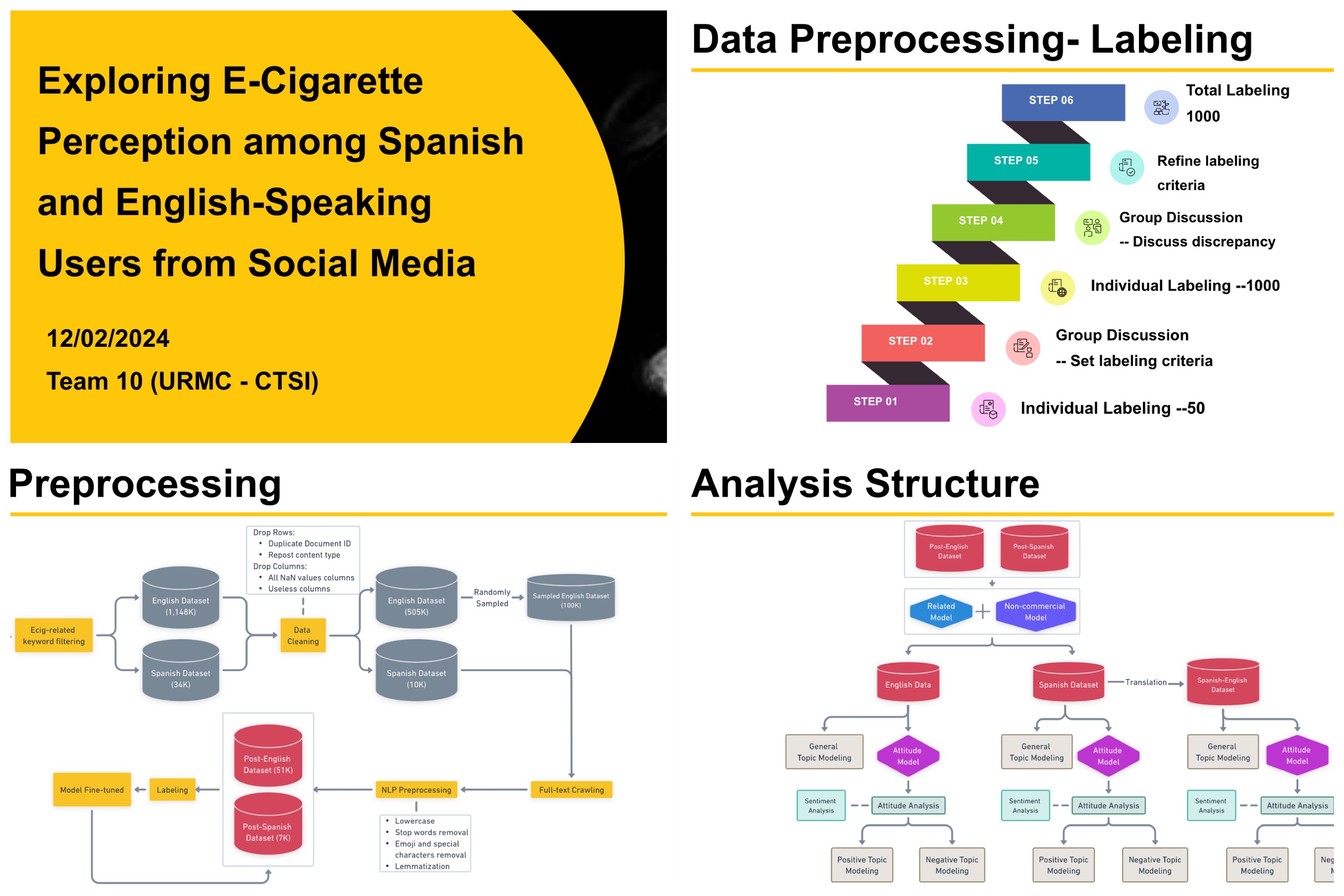
Led a multilingual NLP capstone project analyzing 51K English and 7K Spanish tweets (sampled from 1.1M+ total) to uncover cultural and linguistic differences in public e-cigarette discourse.
The project integrated Transformer-based models and BERTopic clustering to reveal how cultural and linguistic nuances shape online conversations about vaping and health.
Goal: Bridge the gap between multilingual social media analysis and public health strategy by uncovering culturally specific narratives in e-cigarette discussions.
🧩 Dataset & Preprocessing
- Data Source: Third-party provider (keyword-based Twitter/X scraping)
- Dataset Size:
- 1.1M English tweets → 51K after cleaning
- 34K Spanish tweets → 7K after cleaning
- Preprocessing Pipeline:
- Deduplication and retweet removal
- Full-text crawling for truncated tweets
- Tokenization, lemmatization, emoji/special character filtering
- Text normalization for both English and Spanish corpora
🧠 Model Training & Fine-Tuning
Built and fine-tuned multiple Transformer-based classifiers to detect multilingual relevance, commercial intent, and attitude toward e-cigarettes.
-
Relevance Classification:
→ Model: BERTweet
→ Accuracy: 96%, F1: 0.85 -
Commercial Intent Detection:
→ Model: BERTweet
→ Accuracy: 93%, F1: 0.87 -
Attitude Classification (Positive / Neutral / Negative):
→ Model: Twitter Twin BERT Large
→ Accuracy: 92%, F1: 0.89 - Manual Labeling: 1,000 tweets labeled through iterative consensus across annotators.
- Experiment Tracking: Comparative evaluations conducted via Hugging Face Transformers and custom Python scripts.
🔍 Topic Modeling Framework
- Pipeline: Sentence-BERT embeddings → UMAP (dim. reduction) → K-Means clustering
- Model Comparison: TF-IDF, LDA, and BERTopic evaluated
- Final Selection: BERTopic for best coherence and topic diversity
- LLM Integration: OpenAI-based LLMs used for iterative topic naming (100+ refinements)
📊 Key Findings
- Cross-Linguistic Insights:
- English tweets: Focused on regulation, youth vaping, and health risks
- Spanish tweets: Emphasized social lifestyle, recreation, and cultural expression
- Translation revealed sentiment dilution — idioms and slang often lost nuance
- Sentiment vs. Attitude:
- Traditional sentiment (VADER): Majority neutral
- Fine-tuned attitude model: 41.2% negative, 24.6% positive, 34.2% neutral — exposed hidden polarization
- Translation Drift:
- Spanish originals: addiction, cravings, habit discussions
- Translations: introduced consumer and gifting themes not found in native tweets
⚙️ Challenges
- Subjective Labeling: Cross-cultural definitions of “positive/negative” required careful alignment
- Translation Fidelity: Idioms, emojis, and slang were inconsistently captured in MT pipelines
- Dataset Imbalance: English tweets outnumbered Spanish by ~7:1
- Cross-Language Topic Coherence: Syntactic variations reduced cluster interpretability
- Demographic Bias: Twitter users may not represent broader population sentiment
🚀 Future Work
- Develop cross-lingual topic alignment models to reduce translation drift
- Expand labeled data for better multilingual fine-tuning
- Perform temporal sentiment tracking around policy updates and major public health events
📄 Full Report: E-Cigarette Perception Analysis (PDF)
📘 Keywords:
Multilingual NLP | BERTweet | Sentence-BERT | BERTopic | Cross-Linguistic Analysis |
Transformer Models | Public Health | UMAP | Clustering | Cultural Interpretation