Wonha (Leah) Shin

Machine Learning & MLOps Engineer
I design, build, and scale intelligent systems — from streaming NLP pipelines to real-time LLM applications. Driven by curiosity, I combine data engineering with AI research to turn ideas into production-ready systems.
View My LinkedIn Profile
🏨 Cross-Cultural NLP Analysis of Luxury Hotel Reviews in Europe — LDA Topic Modeling
Python | Gensim | Scikit-learn | LDA | NMF | Clustering | Tableau | R | NLP | Topic Modeling
🌍 Overview
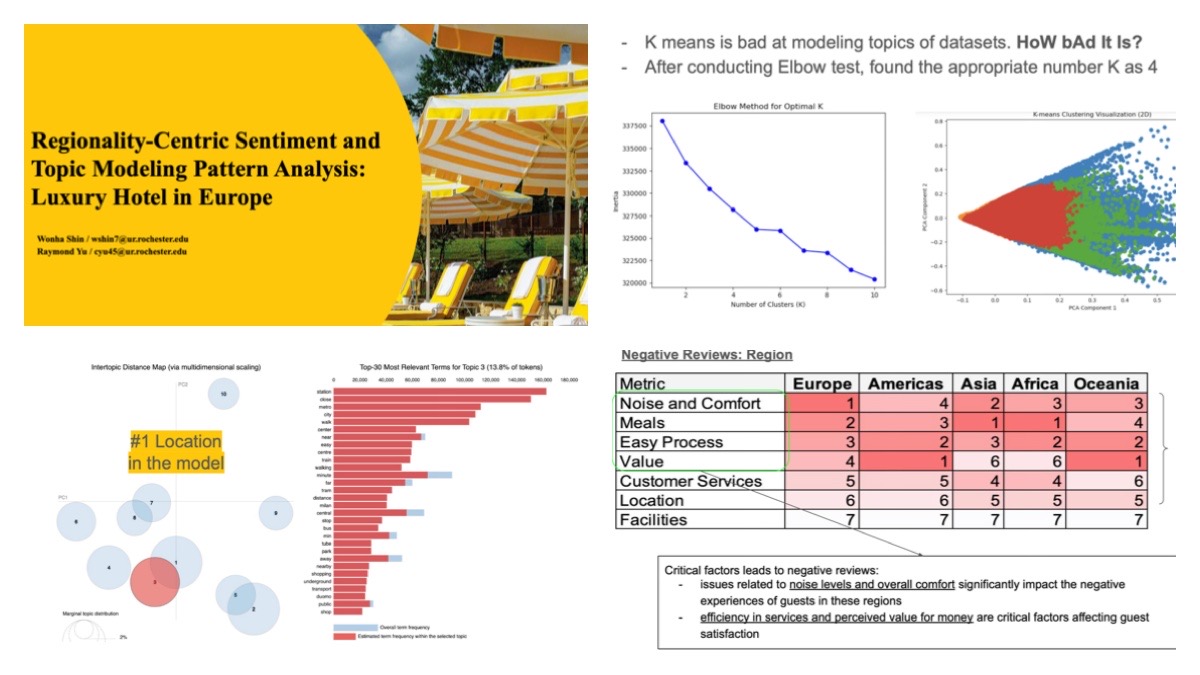
Conducted a comprehensive NLP analysis on 515,000 luxury hotel reviews across Europe to uncover latent customer satisfaction patterns and regional sentiment differences.
This project combines unsupervised topic modeling (LDA, NMF, Clustering) with cross-cultural analysis to explore how travelers from different nationalities prioritize various aspects of luxury stays.
Goal: Go beyond ratings — understand why guests feel satisfied or disappointed, and reveal how cultural factors influence luxury travel experiences.
🧩 Dataset & Preprocessing
- Data Source: Kaggle — “515K Hotel Reviews Data in Europe” (Booking.com)
- Size: 515K reviews from 1,493 hotels across Europe
- Cleaning & Structuring:
- Removed duplicates, handled missing data, trimmed whitespace
- Created a concept hierarchy for regional groupings based on Google Maps
- Tokenized, lemmatized, and vectorized reviews using TF-IDF and Bag-of-Words
🧠 Methods
Applied a suite of unsupervised learning algorithms for thematic and cluster-based segmentation:
- TF-IDF + K-Means Clustering: Identify high-level review groupings
- LDA (Latent Dirichlet Allocation): Extract interpretable latent topics
- NMF (Non-negative Matrix Factorization): Validate topic coherence and sentiment separation
- Comparative Analysis: Combined with R and Tableau for quantitative and visual evaluation
🔍 LDA Topic Modeling (Gensim Implementation)
- Corpus Construction:
- Built dictionary → Bag-of-Words vectorization → TF-IDF transformation
- Optimization:
- Tuned over 50 iterations to maximize topic coherence
- Adjusted
num_topics,passes, anditerationsfor model stability
- Results:
- High coherence across models
- Meaningful topic clusters reflecting distinct traveler preferences
📊 Findings
- Regional Insights:
- Europe: Focused on noise, comfort, and value for money
- Asia & Africa: Strong emphasis on meals and dining quality
- America: Value for money drives most negative reviews
- Positive Review Themes: Cleanliness, service, and staff hospitality
- Negative Review Drivers: Noise, food dissatisfaction, and operational inefficiency
- Cultural Context: Eastern Asia valued customer service highest — unmet expectations amplified negative sentiment
🖼️ Presentation & Deliverables
📎 Slides: Hotel Review Analysis Slides (PDF)
📄 Full Report: Hotel Review Analysis Report (PDF)
📘 Keywords:
NLP | Topic Modeling | Gensim | Scikit-learn | LDA | NMF |
Clustering | Tableau | Cross-Cultural Analysis | Data Visualization